(Dog-Eared) Airport Cities

On the morning I left New York City to go to Philadelphia, last month, I went for coffee with some friends. At one point we were talking about how email itself seemed to be going the way of letter writing. That is: no one really wrote much email anymore, at least not if you excluded the one or two line grunts that we pass one another as part of the daily grind. This is the usually the point where someone says something about a new media supplanting an old one — these days it is still microblogging
but I'm sure the webinar
people are warming the brand-porn cannon as I write this, right Myles? — but I think it might be something else.
I think it might be the expectation that sooner or later those conversations we used to have in written form will just happen face to face. And it's the sooner or later part that's important. It's true that things like Twitter make it possible to be just dimly aware enough of what's going on in someone's life that it helps to chip away at the first 20 minutes of awful awkwardness that you always experience when you see someone after a long absence and wonder if you're ever going to be friends again but that's just the grease, so to speak, and not the wheel. What's interesting is the idea that we no longer consider it exceptional to travel across continents, or oceans, in a day or less (save for the physics involved which are doubly involved if you happen to be afraid of flying) and we have started to take for granted levels of intimacies with people far far away normally reserved for those in the same city.
There's no shortage of privilege and questionable sustainability in those last two paragraphs and in many ways is not unlike the generally repellant boosterism of futurists and airline executives. What seems different, maybe sorta kinda, is that it's an idea which is manifesting itself in a quieter way than the lifestyle adventures we've been sold in the past. I don't think I am alone in joking that San Francisco and New York have, effectively, become neighbourhoods to one another. This is especially true if you take a red-eye between the two cities and manage to sleep during the flight only to wake up on the subway inbound to Manhattan. Given how awful the buses are in San Francisco it feels easier, conceptually (or emotionally) at least, to leave the Mission and go for breakfast in Brooklyn than it does to travel to the Marina for dinner.
Like I said: A lot of privilege and deferred realities but it is a luxury that is becoming available to more and more people and it is the manner of nurturing relationships that airplanes seem to afford which fascinates me.
I don't have a good answer for why I still faff around making maps instead of finding a proper alternative to jet fuel when I came to the conclusion that, on measure and despite all its environmental short comings, plane travel is a genuinely Good Thing. If you subscribe to a particular crunchy worldview that advocates bringing people together, bridging cultural differences and fostering empathy across geography then it's hard to find anything that's done a better job of that than the airplane. I have hope, for most of the reasons I've described above, that the unquestionable homogeniety across places that plane travel has encouraged is really just a passing phase and a growing pain in the same way that I have hope (read: hand-waving) that we will figure out a viable alternative to jet fuel.
(Also, who the fuck let the hippies back in to New York with all their woolen coffee sleeves?)
In the 80s we realized that refridgerators were almost single-handedly poking irreperable holes in the ozone layer so we made better fridges. No one even deigned to suggest that we get rid of fridges because, well, yeah... just try to imagine what life would be like without a fridge. Given the choice between fridges and plane travel I would choose the former but I want to live in a world where airplanes are a good idea that still need to be done properly.
So, that's the setup for two things that happened within a day or two of one another: I made a new slippy map called Airport City
and started reading Greg Lindsay's Aerotropolis
.
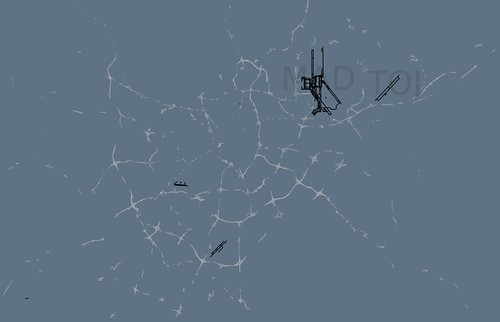
There isn't much to say about Airport City that the about page doesn't already say: It's a slippy map made of nothing but things tagged aeroway or whose highway tag is a kind of on or off ramp in OpenStreetMap. Which is to say:
I became fascinated with the on and off ramps, in OSM, during and still following the creation of prettymaps in 2010. To see them in isolation is to see the gravitation push and pull (the wind patterns and dance moves) of the cities they make possible.
Airports seem like a natural pairing for on/off ramps since they occupy a similar function to on/off ramps despite their
mechanicaldifferences. Particularly the runways which are either overlooked entirely or forgotten in the rush of leaping in to the sky or the anticipation of returning to solid ground.I like to look at them, rendered in isolation, and imagine them lumbering across the landscape like tankers or cargo ships at sea. Or as new pieces in a very large and very slow-moving chess game that is still looking for its arc.
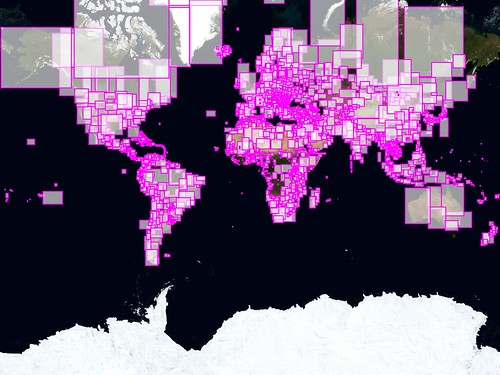
Airport City is a(n ongoing) good example of how not to render map tiles. Airport City consists of two separate, layered, tilesets that span zoom levels 3 to 13. The first layer consists of the airports and highways; the second has the corresponding airport codes that are lain underneath. The rule of thumb when rendering map tiles (on your own) is: zoom levels 1-9 are easy; zoom level 10 is where things start to become hard; zoom level 16 is where things start to become impossible.
Zoom level 13, it turns out, is where things start to feel impossible. Zoom level 13 is 67 million tiles or 128GB of disk space (not to mention inodes which are the other dirty little secret of rendering map tiles). Because most of the planet is actually water I decided to use the most Flickr shapefiles, which are conveniently separated by place type, as a kind of mask
when rendering tiles which really just meant generating a shell script with a call to tilestache-seed.py for each bounding box.
Even then I made a series of naively optimistic mistakes despite knowing better:
- Running Tilestache with a
portable
disk cache. Seriously, just don't ever do this for anything larger than a neighbourhood or, if you're feeling dangerous, a small city. Despite all the magic future talk we still live in a world where Unix filesystems get unhappy when you put more than a thousand (or so) files in a single directory and don't plan on doing much else on a machine that needs to delete ten or eleven zoom levels worth of tiles for the entire world when they've all been tossed in to two or three folders... - Copying the tiles to S3. Again, just don't ever do this. It's a fantastic waste of time and money, pretty much as soon as you hit zoom level 11. I did it for zoom levels 1-10 for shapetiles.spum.org and it cost me about 50$ in transfer fees but if I had to do it again I would do what we did for the 47GB worth of tiles that make up prettymaps: Mount an EBS volume and just rsync them. John Allspaw also recommended using Netcat because he is smart that way. If you really need to put your tiles in S3 at least do it once their already inside Amazon's network and you can transfer them in the background for no (additional) cost. I finally stopped trying to copy 342 gigabytes (remember 2 * zooms 3-13) worth of tiles, one at a time doing the AWS authentication dance for each, after about two weeks and ~ 100$ worth of transfer fees. Because I am dumb that way.
- Being overly optimistic about the part where most of the tiles have nothing in them. Especially at high zoom levels which is where most of the tiles are. Zoom level 3? 64 tiles. Zoom level 10? 1 million tiles. Zoom level 13? 67 million tiles. And then trying to copy them all in to S3. I am still cleaning up this particular mistake. This is probably still an edge case since the idea that a map wouldn't have anything in it, at least over land, is sort of antithetical to the way we think of maps. Except for the part where I think we'll see a lot more maps like Airport City in the future and then we'll need to figure out how to deal with NULL tiles at the layer where the tools that generate the tiles operate. Some slippy-map libraries like Polymaps already handle missing tiles gracefully (that is, they don't display a broken or missing image icon) and Amazon recently tweaked S3 to be able to return a pre-defined document, or image, when it would otherwise return
404 NOT FOUNDbut other tools, like Mapnik will happily churn out one empty tile image after another instead of... well, I'm not really sure what it should do instead. That's the work, isn't it?
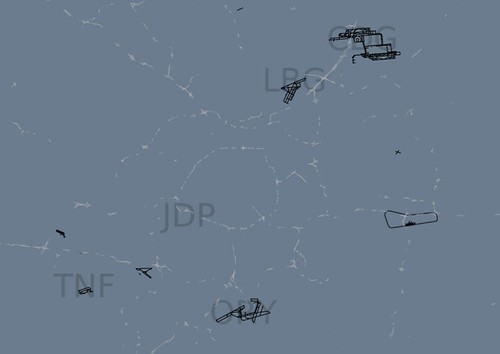
But somehow it is up and running and a few days after pushing it live Tom Carden was kind enough to implement smooth panning and zooming for Polymaps and now Airport City can be set to run automatically jumping from one airport to another every 20 seconds or so. Sadly, this sort of thing still demands too much today's tablets so I'll have to buy a cheap iMac, or maybe a plug computer and a broke-ass display, in order to run it on the wall in my living room.
And since then I've been reading Greg Lindsay's (and John Kasarda's) Aerotropolis which I would recommend and which I will surely read again and to which I am generally predisposed to agree with except for the part where it presupposes a particularly grim meathook Darwinianism that I have a lot of trouble with. There is merit to the both the analysis and the arguments the book makes but it comes wrapped in no shortage of resistance is futile
style inevitabilities whose core assumption is that left unchecked we are all assholes and that globalization belongs to the fastest assholes around.
I don't normally do dog-eared
blog posts but since all my notes only exist (if you can call it that) somewhere inside Amazon's hive-mind and I don't trust them to have any longevity there I am including them here for posterity. There's a whole blog post about how insanely annoying Amazon makes the process of doing anything with your notes, not least of which is a working version of the Kindle for the web so that I might include sane links to passages (unlike the ones I've included below) but that's a story for another day. Anyway, all the usual caveats apply:
- Nearly a billion people are a day trip away. #81
- the logic of globalization made flesh in the form of cities. #104
- Kasarda’s mother tongue is academic jargon leavened by the argot of business bestsellers. #123
- "The Global Air Cargo–Industrial Complexes" #144
- Half the battle in any market is now fought by invisible armies of suppliers, any of which might be arming both sides. #159
- or else this flat world we’ve gotten used to will remember its former shape. #165
- building one from scratch out of pure anticipation, #252
- while cities grow organically, airports cannot. #317
- slices of our self-interest? #359
- our slightest whims, multiplied several billion times and duly noted by the marketplace, #363
- abutting the runway fences, were the free-trade zones, #391
- the twin calamities #413
- The world may or may not have flattened since then, but there’s a lot less changing planes. #434
- we built our airports before we knew what they were for. #519
- and another $20 million went to pay for residents’ soundproofing. In response, the airport began buying homes outright and knocking them down—some thirty-five hundred to date. Westchester has begun to disappear, street by street and block by block. #573
- When you look at the value of the cargo, though, we have eighty percent.” #655
- At any given moment, there are aloft “incomprehensible quantities of the mundane,” in the words of one such witness: #661
- pilots must lock the brakes, power up the engines to full throttle, and then release, hurtling down the short runway at top speed before climbing as steeply as possible. Then, just five hundred feet in the air, they all but kill the power so as not to wake the neighbors. Not until after they’ve floated out over the Pacific do they resume their ascent. #700
- moored a dozen miles out to sea, with runways on the roof and an aerotropolis larger than San Diego itself stowed below. #751
- In exchange for its cash, the Pentagon made itself the impatient center of their universe. #788
- So Dulles was where you went to extract cash from the federal government. Soon whole companies moved #793
- if its size was measured in mall and office space, #805
- “Dulles” is an alternative name for the town of Sterling, which has been summarily dumped in favor of #830
- just enough wiggle room to find their true purpose. #1163
- a sweet spot of climate and time zones #1213
- It actually consumes more electricity than the entire waterfront at night, #1290
- Flipping the box demands human intervention, however, as the software is helpless until it can see the label. #1321
- The company’s term for it is “de-skilling,” #1352
- We just happened to start with shoes the same way Amazon just happened to start with books.” #1407
- Its location is noted by Zappos’ omniscient inventory system, named Genghis, and forgotten by everyone else. #1454
- The experience hadn’t changed, and the prices were still the same, but free shipping triggered a Pavlovian response. #1511
- What the Internet added to the retail equation wasn’t long tails and thoughtful comparison shopping, but the acceleration of impulse. #1531
- The shapes of both aerotropoli sprawl along the splines of I-65 in Kentucky and I-55, I-40, U.S. 72, and U.S. 78 through Tennessee and Mississippi. They have lapsed into what Robert Lang of the Brookings Institution has dubbed “edgeless cities”—fuzzy patches of urbanity dispersed across hundreds of square miles and barely knit together by roads. #1660
- Cargo doesn’t need quality of life. #1671
- To help prepare them for the immensity of their undertaking, they drafted the landscape artist Robert Smithson, who learned more about art from them than they were able to glean from him. #1867
- They’re amnesiac places with no future and no past, only a continual present offering the same choices—flights, #1924
- Airworld is a nation within a nation, with its own language, architecture, mood, and even its own currency—the token economy of airline bonus miles that I’ve come to value more than dollars. Inflation doesn’t degrade them. They’re not taxed. They’re private property in its purest form. #1955
- Strip away the logos, and they would find themselves flying in metal tubes, striding through steel corridors, driving cars that are not their own, and sleeping in rooms just vacated by others. No wonder they cling to brands in such places, #2027
- Topus does his best work canvassing first-class cabins #2123
- The setting is pure node—white space—the incarnation of an Internet chat room. #2135
- Las Vegas hosts nearly a quarter of America’s two hundred largest trade shows, generating $8 billion a year—more than all of the Strip’s casinos. #2173
- “community without propinquity,” #2295
- location is trumped by access, #2320
- The time we spend commuting has never changed, only our modes of transportation have. #2326
- the white-collar capital of the Metroplex. #2420
- The company calls this “worldsourcing.” #2503
- All of the software companies have major, major physical plants around the world. And I think those are going to start going away,” #2524
- In light of this, plane tickets can be a smarter investment than an office lease. #2531
- Should an airport be allowed to pursue tenants who could exist outside it?” In other words, is it in the aviation business, the real estate business, or the urban planning business? The answer is all three. #2552
- shattering Brian’s concentration while he watched Star Trek. #2591
- fifty square miles of land banked for future runways, terminals, and anything else it needs, #2619
- Noise contours #2643
- the eastern tip of Denver (including the once and future Stapleton), the “Aeropolitan” (as local boosters once called it) #2650
- The geographer David Harvey calls this the “spatial fix” of each era, with “fix” having multiple meanings. #2682
- and a voracious robotic baggage system craving Samsonites. #2698
- the Arvida Corporation, Disney’s wholly owned designer of gated golf course communities. #2715
- The deciding factor, he surmised, was “research” conducted by the CEO after a round of golf. #2752
- “They’ve coined terms to capture the polymorphous living arrangements found in these fast growing regions: edgeless city, major diversification center, multicentered net, ruraburbia, boomburg, spread city, technoburb, suburban growth corridor, sprinkler cities.” #2894
- “They’ve coined terms to capture the polymorphous living arrangements found in these fast growing regions: edgeless city, major diversification center, multicentered net, ruraburbia, boomburg, spread city, technoburb, suburban growth corridor, sprinkler cities.” #2894
- they’d torn up the runways, pulverizing the tarmac into six million tons of pebbles piled in Commerce City, forming the only mountain lying east of Denver. #2916
- the city council approved plans for an aerotropolis the size of San Francisco on the edge of the desert. #3063
- The failure of most American cities to connect their airports to downtown with trains (or to do so hopelessly after the fact) will go down as yet another of our great infrastructure blunders. #3077
- need for a central transit hub, which allows for more uses.” #3104
- having a system of transportation that links this density into a larger context is what’s important. #3107
- If you develop a very efficient transit system and build it close to an airport, every stop is ultimately an opportunity to build out the airport. The airport starts to spread as it develops access to places beyond its borders. The more tightly integrated it is into the city, the more the airport becomes a city. Until it’s everywhere.” #3117
- the laws of natural selection that had produced Kasarda’s aerotropolis. #3152
- “The world within which man lives,” he wrote, “is defined less by the horizon of his geographical knowledge than by the limits imposed by his means of transportation and communication.” #3155
- Its mix of high skills and low wages make it the place where even Indian firms send programmers to work on American time. #3274
- from a widow’s peak like the wings of a stealth bomber. #3422
- if you allow it to stand in for the pervasive wiring of the world over the past forty years and all the changes it has wrought. #3463
- Not that he was wrong—each ringleader flew here scheming to raise a new city beyond the ruins of his own. #3549
- Turf is antithetical to the aerotropolis. #3701
- it’s that economic geography now trumps all other kinds. #3830
- The airport is only an excuse to build a city around the train stops. #3883
- Every bubble, at its core, was a bet on greater global integration—whether #4119
- To unwind the chain of ruinous contracts, the courts ruled they were indeed gambling losses, not debts, and the losers walked away more or less unscathed. As with the railroad and Internet bubbles to come, the orgy of spending in the run-up to its bursting paid for the infrastructure that cemented Holland’s dominance in floriculture. Thanks to their monomania, the Dutch had become the undisputed masters in breeding, growing, and trading bulbs, inheriting the industry from the Turks. #4124
- the efficiency gained from bringing so much infrastructure to bear on a hub offsets any lag introduced in moving them here. #4210
- the commercial extinction #4347
- with proof of virtue, #4553
- The difficulty, they soon discovered, is that no one can agree on where the life cycle of a lamb or lettuce begins or ends. #4560
- Once again we’re debating virtue, #4586
- Trade—often long-distance trade—would be assumed, but everything at the hubs would be open to regimes of improved efficiency,” #4719
- The repeal of geography #4788
- web of just-in-time airstrips. #4860
- The most controversial recommendation does not appear anywhere in the executive summary: the legal creation of Nakhon Suvarnabhumi as Thailand’s seventy-seventh province, #4918
- grafting a competitive weapon onto a host that had rejected the transplant. #5149
- Or, as the head of the UNWTO put it, “Tourism is the best foreign direct investment system ever invented.” #5198
- “Your options are paying fifty to sixty thousand dollars in the States or coming here and paying eight thousand,” said Toral. “That’s the difference between putting it on your credit card or going into bankruptcy.” #5230
- shipped in bulk from Riyadh and Dubai because Toral cut a deal with their governments to outsource their surgeries here. Medical tourism, Toral told me, is only the beginning. The next step is globalized medicine, in which millions of fully insured patients in the United States will be flown to hospitals in Bangkok, Singapore, and India for treatment. #5242
- We’re going to have the same thing—just-in-time patients. #5307
- The danger is that someone else will siphon them away with lower costs and better connectivity in the form of nonstop flights; layovers are not an option when you’ve just come out of traction. #5443
- Not long after Bengaluru opened, Gopinath (whose airline called it home) began flying helicopters from the old airport to the new, selling seats for $100 each way on the ten-minute hop. #5556
- Unwinding its untenable positions entailed the world’s awe curdling into schadenfreude. #5733
- places where the global overclass owns homes, yet has no intention of living full-time. #5764
- “Dubai is full of ‘tourists,’ ” he said, “but they aren’t the tourists we know. These are economic tourists, and they’re coming from the Middle East and eastern Africa for the express purpose of shopping, because there is nothing to buy where they are. We don’t get it in the West because while we live in a world that is overstocked, they live in a world that is understocked. The tourists Dubai is reaching out to are a giant audience whose appetites just aren’t as jaded as ours.” #5867
- blinded by the reflection of our own inequality, unsustainability, stupidity, and greed. #5883
- the pair separated only by the surface tension of extreme inequality and the threat of deportation. #5948
- It’s turning the source of America’s last great competitive advantage—its unmatched universities—against itself, counting on Harvard and Yale to think like brand managers and multinationals rather than national trusts. They seem to have forgotten in their haste to go global that America thrived by drawing the planet’s talent to its shores and then convincing it to stay awhile. #6074
- “functional renewal.” #6187
- They landed en masse once China joined the WTO, cutting out the middlemen in Hong Kong by tracing their supplies to the source. #6305
- languorousness. #6383
- Fifty years of refinements have yielded engines cleaner by an order of magnitude, but any gains in efficiency have been far outpaced by exponential growth in the number of passengers—the inevitable result of falling costs and ticket prices. #6456
- change—entwined in a single, suicidal braid. #6472
- Before dismissing air travel as hopelessly dirty and delayed, we might make an honest effort to clean and fix it. #6952
- And so we made a point to avoid abstraction, choosing collage instead.” #7004
- It’s no coincidence that Gale’s following the airports. #7052
- It’s the promise of taking the definition of an unsustainable way of life to global scale without deprivation and without poisoning ourselves. #7062
- The only thing faster than a FedEx 777 Freighter out of Hong Kong is the velocity of money, and the last thing Casey wants to pay for are the days his parcels are stuck on a boat. Obsolescence sets in the moment they leave the factory. “Revenue evaporation,” he calls it. #7118
- “What ASUSTeK proved is that the companies with real leverage are the ones that actually make desirable products,” #7319
- FedEx had sought equally drastic changes to China’s legal code, rewriting customs and aviation statutes to grant itself an unlimited number of flights. #7352
- It’s now the store versus the factory, #7364
- As a report by the American Chamber of Commerce in Hong Kong put it: “Clothing is increasingly considered a perishable good.” #7411
- The airports receive top billing, he said, because they are the best proxies for the region’s balance of power. #7459
- Now we’re trying to overestimate and see where we are five years from now.” #7695
- By the time they’re finished in 2020, 82 percent of the population—1.5 billion people—will live within a ninety-minute drive of an airport, nearly twice the number today. #7699
- The answer: ten fully loaded 747s a day, every day, forever. And that’s just for laptops; #7864
- Luxury had been rendered obsolete by speed. From then on, speed itself was the luxury. #8143
- the subliminal hum of jet wash #8167
- The history of Chicago’s airports is mostly drawn from the Chicago Tribune’s Pultizer Prize–winning report published in November 2000. #8281
- Michel van Wijk’s Airports as Cityports in the City-Region #8439
- The idea that all financial bubbles are bets on globalization is suggested in Michael Pettis’s The Volatility Machine and Peter Thiel’s “The Optimistic Thought Experiment” #8459
- Japan Airlines sent me Akira Okazaki’s final report on the events leading up to “the day of the flying fish,” which also appears in Sasha Issenberg’s The Sushi Economy. #8469
- China’s airport strategy is laid out in the Eleventh Five-Year Plan, available on the government’s website, www.gov.cn/english/special/115y_index.htm. #8683
Now I am reading a book about seeing the world from airplanes whose first few chapters document the work of the photographer Micheal Light, whose work popped up on 20x200 recently, which is nice because the two people I went for coffee with at the beginning of this blog post are Sara and David who both work at 20x200!
This blog post is full of links.
#airportcity(Authority Records, Future Computers and Other) Unfinished Histories

There was a time when this blog was being powered by some very brittle mod_perl code that read from a database which meant that most of time it only ever served up a HTTP 500 Server Error page. For a while I just started publishing my blog posts to that one static page, by hand. Once again I am IN THE MOTHERFUCKING SKY as I write this and starting to think that maybe I will only write blog posts from airplanes from now on. If I do I will rename my blogging tools Zeppelin
in honour of Myles.
So, here I am heading home after another year at Museums and the Web. I've always felt it is a great privilege that the amazing people who attend MW tolerate (even encourage, sometimes) my swooping out of the sky every year to come and wave my arms around before dashing off again to leave them to the truly hard work of getting shit done day in and day out. This year was a lot like the first time I spoke at Museums and the Web because I was presenting an argument for which I don't have a ready solution. More specifically, there is no one solution but when you look at the landscape today and expand it out a few years out it's hard not to think that museums (which is just a short-hand for anyone working in cultural heritage or the digital humanties) are facing a problem that needs to be addressed sooner and before there is no later.
As always, being given the opportunity to speak at Museums and the Web means writing a paper first and this one was the most difficult in the four years I've spoken at MW. It was difficult because it is one of those subjects that can quickly turn in to a noodle-y shit-storm of creeping ideas and, worse, become ranty and shrill without anyone noticing. One good thing about a subject that is vexing you is the opportunity to talk to a lot of people about if only to be forced to work out what you're thinking. The need of the MW conference organizers to put together a proper website and publish selected papers in advance of the event meant that (even though I continue to be given outrageous amounts of grace time) some of my thinking didn't make it in to the final capital-P paper which was already a bit harried to start with. I am grateful to Jennifer and David that they continue to keep taking the leap of faith and letting me speak as the years go by.
I wrote my talk thinking I had a little less time to speak than I did and so I narrowed the examples down to OpenStreetMap because it's such a powerful and trumpet-blaring demonstration of what communities can get up to on their own. On the last day of the conference Fiona Romeo knocked it out of the park with her presentation on citizen scientists and historians and if I ever do this particular talk again I will be all over the stuff she talked about. Even if you don't bother reading the rest of this blog post, just go read Fiona's paper.
This is what I said:

Hi, my name is Aaron. I am from the Internet. These days I work with Stamen Design, in San Francisco. We are a design and technology studio and so my official title is Design Technologist
. It’s not a title that I’ve ever really warmed up to but it just means that we value working code and real live data over mock up and high-minded concept pieces. Before that I spent five years helping to nurture the 800-pound baby most people know as Flickr
. I am also on the advisory board for the Built Works Registry, which is an IMLS funded project to create a registry of architectural works that plays nicely with both scholars and the Internet at large.

Most importantly though, I am the co-director of revolution technologies, along with Seb Chan, for the Spinny Bar Historical Society! The Society was born at Museums and the Web in 2009 or 2010 depending on how you’re counting. This year, we have stickers!

This is a session about linked data which is, by and large, a technical subject. I am not going to talk about the technical parts even though I could spend hours doing so. I’m here for the whole conference so please come find me if you’d like to talk about the plumbing.
Instead I’d like to approach the subject from a bit of a sideways angle and start with something I said at last year’s Museums and the Web. I was doing a talk about the Galleries project at Flickr and the larger trend which could be described as a nascent curatorial muscle that more and more people, across all walks of life, were discovering.
At the time it seemed like a bit of a funny-ha-ha throwaway comment but it’s stuck with me ever since. What I said was this:

If you, as curators and archivists and generally anyone involved in the preservation of promotion of cultural heritage, think that the authority record is the pinnacle of your careers – that is, the most important thing you will leave behind – then you are about to be eaten by robots.
A year later I would still say the same thing but differently. What I will say instead is that the single most important – and most interesting – question facing anyone who self identifies with the humanities or the arts is what to do about communities of amateurs and enthusiasts.
What does that mean?

The good news is that it means you have a lot of people who are eager to help you in the process of recording and classifying and describing the works, whether it’s a painting or a building or an idea, that make up the histories we tell ourselves.
The bad news, if you look at that way, is that it means they’re going to help you whether or not you want them to.
In the absence of any other means to participate people can and will just do it themselves.
They will self-organize. This is what the Internet has taught us. That it is the fastest cheapest bridge we’ve ever seen for collapsing the barriers of collecting, vetting and redistributing data.
Eventually, if a project gets off the ground (not all do) it will exist not just as an alternative to yours but in opposition to it. Once that happens any mistakes they make will be treated as badges of honour. And they will make mistakes, many of them the same mistakes you’ve made over the years and wouldn’t wish on your worst enemies. But they will also fix them. And in fixing them they will celebrate their resilience and their ability to nurture a collaborative project that can survive those mistakes.

Normally, the poster child for the argument I am making is Wikipedia but I’d like to look at the OpenStreetMap, or OSM, project instead. OSM was born of not quite the frustrations I’ve been describing but they are still a good example of what I’m talking about.
Six, maybe seven, years ago OSM did not exist. At the time the only comprehensive geographic data available in the UK was what the Ordinance Survey had collected but then re- licensed under prohibitive terms despite being a crown, or public, corporation.
OSM started with the premise that if I mapped my neighbourhood and you mapped your neighbourhood and we combined our efforts then we would each have a better map. Not only that but they settled on what seems like the single most absurd way of collecting metadata: Simple, free-form key-value tag pairs governed only by consensus.
If you’re shaking your head over that idea, it’s okay. Everyone did. But now, six years later OSM has a map whose quality matches and exceeds those same maps produced by the Ordinance Survey.
In addition OSM now produces the authoritative maps for parts of the world that have otherwise been neglected because there was neither the time nor the financial incentive to map them. Haiti is the most recent example and OSM is responsible for producing the maps of the country that both the UN and World Bank use on a daily basis.
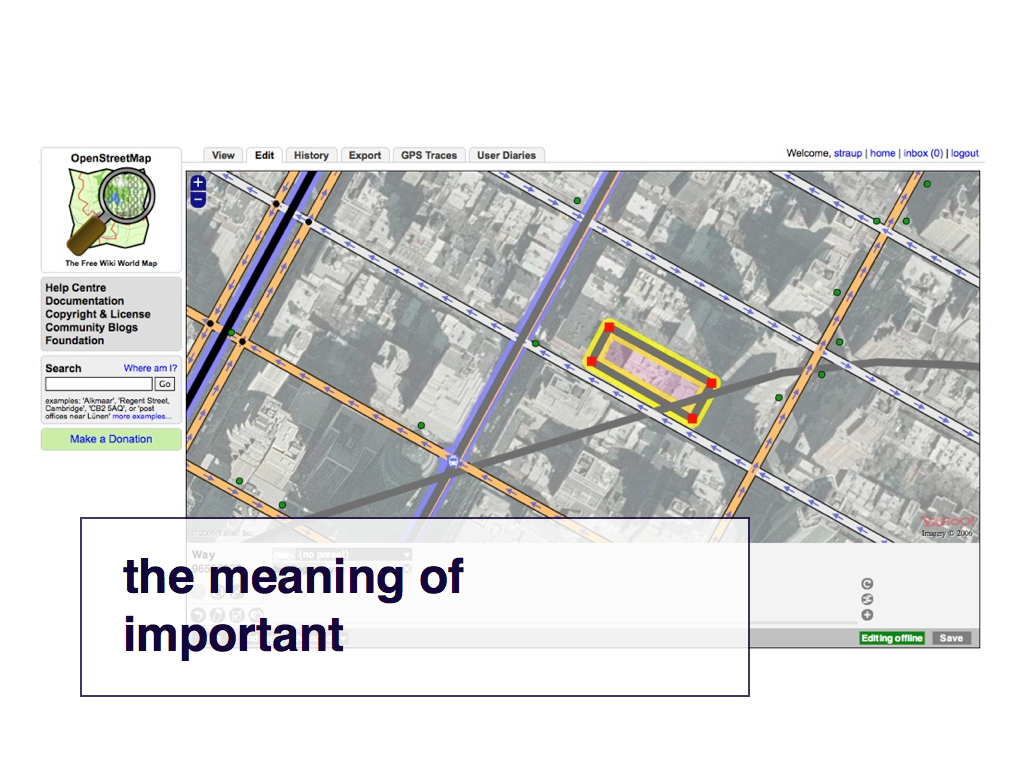
I mentioned that I am on the advisory board for the Built Works Registry. We had our first meeting last January in New York City. I was asked to do a short presentation about what’s going on in geo on the Internet and so, at 06H45 that morning, I added the ARTstor offices, where we were meeting, to OSM.
I did this partly for dramatic effect but also to show that OSM was just one of many parallel registries – of authoritative, linked data – that already existed.
When I showed this slide, James Shulman who is the president of ARTstor said: ...[W]hat seems like a fairly bland, renovated townhouse on the upper east side, now housing ARTstor and another non-profit was originally her townhouse, and the best legend about the house that I've heard was that she commissioned Jackson Pollock to create a mural for the 4th floor. But when he finished it, it was a foot too long to fit on the wall and so she ended up giving it away (http://uima.uiowa.edu/jackson-pollock/). I can't testify to whether this is true or not, but it's a good story about the place...
I have yet to tell that story to a single person who hasn’t thought that was reason enough for the building to be included in a built works registry. That’s just one building in a city where most of its history has happened behind the walls of equally uninteresting
buildings.

Did you know that there are 26 million buildings listed in OpenStreetMap, alone?
This is not one of those buildings, by the way. I had hoped to have a browsable index of all those buildings and all their metadata but life and time got in the way. This is a similar index I made, last year, of the 5 million Where On Earth IDs that make up the Yahoo! GeoPlanet database.
26 million authority records for buildings all over the entire world. Many of those records are probably incomplete but at the very least they all have accurate geolocation information. Some of those records that do have names and other attributes may be incorrect but I’d argue that the principle reason this is the case is because people don’t have good ways to fix them. It's more a question of tools than of motivation.
The OSM community knows full well that the tools that have gotten them this far need help in order for the project to grow but this is the challenge. I’m not here trying to sell you a box package solution. I’m not here to get any of you to sign a contract. I am here to suggest that this the work we need to face in the years to come because the unit of measure for whether or not something is important is no longer dictated by the cost of inclusion.

And to prove that point, here’s the very bad news. It’s not just communities of amateurs that are nipping at your heels. It’s Google and Facebook. The only question in my mind is when, not if, other companies like Amazon start to get involved too.
I should start by saying that I don’t know anyone at Facebook and so what I’m going to propose is a kind of speculative fiction but I think it’s a useful, if only as a warning sign, to stop and consider their OpenGraph initiative as a low-intensity long-term battle with Wikipedia to build a better a dictionary and to become the arbiter of truth for ideas.
The OpenGraph initiative is essentially a re-introduction of <meta> tags for authors to self- describe the content in their webpages. What’s ingenious about the OpenGraph initiative is that it is paired with the even more ubiquitous Like
button which means that Facebook has, for all intents and purposes, built social page-rank
. When anyone actually clicks on a Like
button Facebook knows not only what page is being liked – along with all the metadata in the page – but they also know *who* is pressing the button. When you combine that information with their insanely terrifying but thorough social graph you're essentially turning every webpage on the Internet in to an authority record.
And it’s probably not a mistake that it looks and feels like Google’s page-rank algorithm. If Facebook is just being quiet and deliberate and creepy about the process, Google has in the last year or so pointed its laser-eyes squarely at the digital humanities.
Google has never wavered from their goal of being an information retrieval company because “information retrieval” is just a benign way of saying “everything”. If every natural language researcher on the planet uses Wikipedia as its training set Google was clever enough to realize that they could do what Facebook is trying to do by building a suite of tools – often very good tools – and treat the entire Internet as their training set for teaching robots how to interpret meaning and assign value.

Which sounds pretty awful, doesn't it?
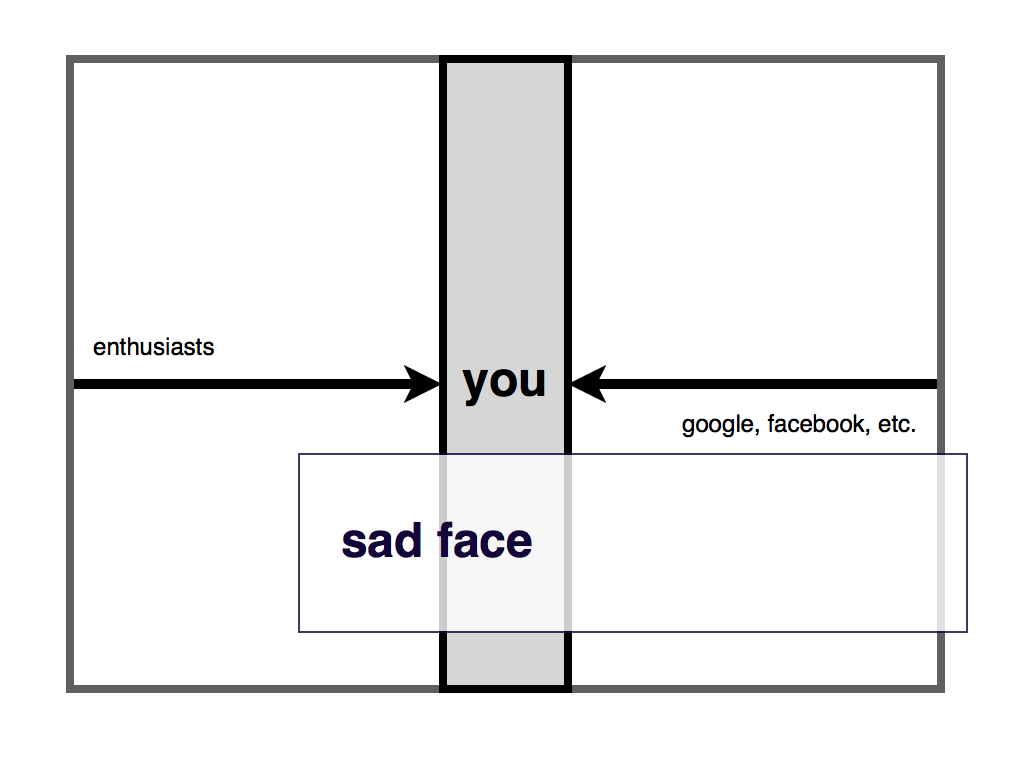
This is more or less what I’ve been describing and, lest you get the wrong idea, it’s not a scenario that I’m particularly happy about.
There’s no guarantee that it will happen this way. It requires not only that you, collectively, stumble but that these other communities actively succeed. But there are enough signs rumbling down the horizon that it’s not simply crazy-talk. It’s something to consider.
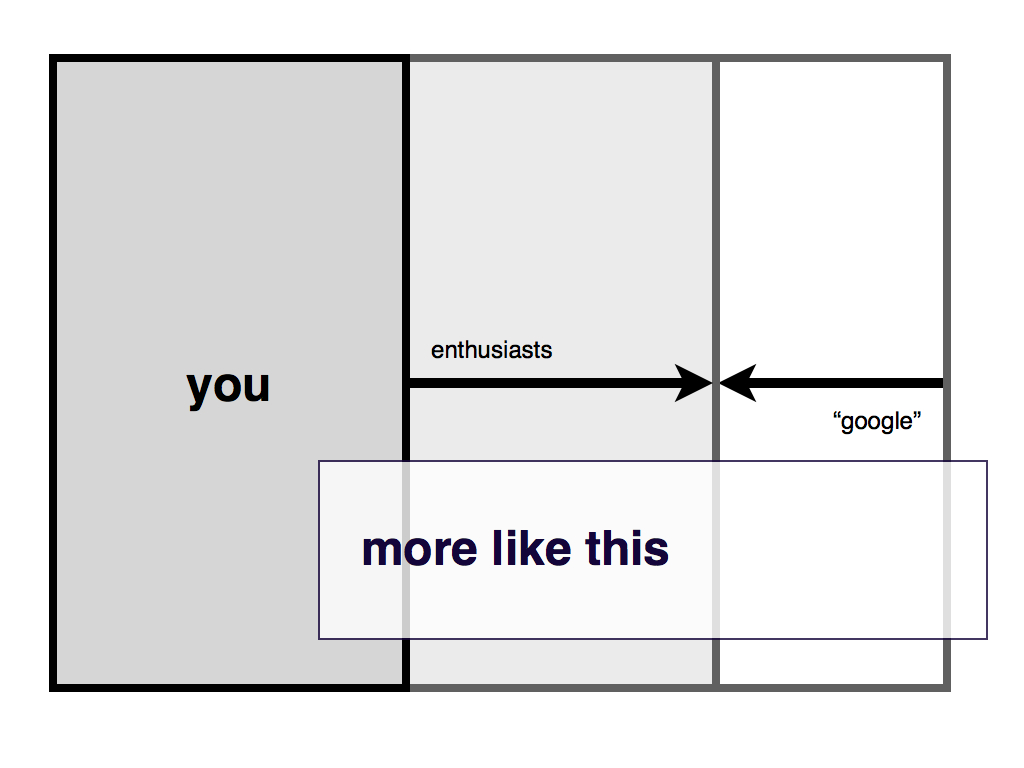
What I am suggesting though is that you turn some of those relationships around in a way that benefits everyone.
Your best defense against being over-run by the likes of Google, or whoever comes after them, is to embrace all those people who are out there waiting to help you. It may seem as though I am suggesting you adopt the tyranny of the commons as a strategy but this kind of (hopefully) mass participation is no longer where the flattening
of meaning and importance will happen.
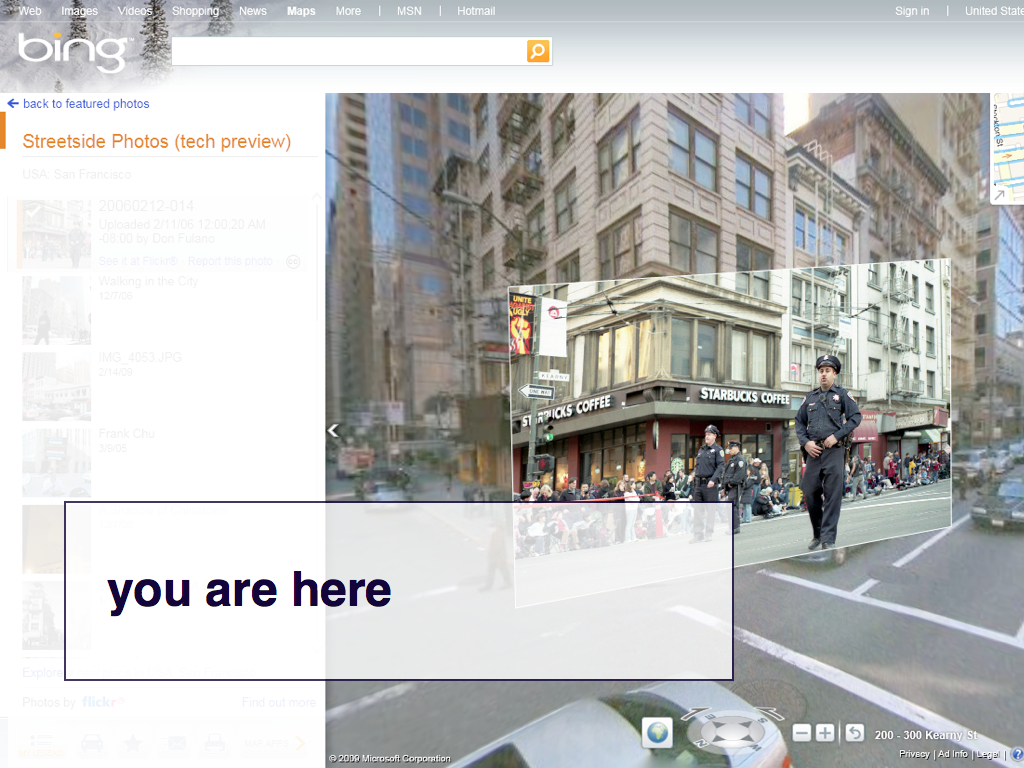
This is a screenshot of Microsoft's Streetside Photos
application integrated with Flickr photos.
The common way of reading this image is that the foreground image celebrates the little person and their contribution to meaning in the face of common and pedestrian understanding represented by single unbroken view point of the background image.
This may be true but what if we turn this idea on its head and say: This is actually your opportunity.
Remember when I said no more complicated than a catalog listing
? Intuitively I think we all know that it is more complicated than that. That there is nuance and disagreement to the works we collect and study. So instead of being the background that photo there in the center represents your work and years of study and your ideas and most importantly your disputes.
Dispute is notoriously difficult to codify, especially in a database, but one of its most important functions is to shine a light on two or more opposing views so that might better see the context in which those ideas exist. I am not suggesting that we do away with structured metadata but this is not necessarily where all of your time is most needed today. You have the gift of magic that no robot will ever have: We call it language
and story-telling and these are the things that you are good at.
So, if you are the center photograph what about the background? The background are the communities of enthusiasts and this is what has changed: They are never going away again.
The days of the proverbial white walls of the gallery that your
photo (the one in the center) used to hang on in glorious isolation are over. This is the new world or more likely it's the world that always existed but has finally found a way to give itself a form that can not be ignored.

I also don’t want to leave you with the idea that you add to your already too busy lives by saying that every single new authority record created by an enthusiast need be vetted by you or your colleagues.
I am saying that by encouraging documentary efforts outside the scope of the contemporary zeitgeist we create a zone of safekeeping for historical records and their stories for a time when we are ready to reconsider them.
I am saying that all those works not yet deemed worthy of a scholar’s attention still have value to people and their inclusion within a larger body of work is an important and powerful gesture for encouraging participation. Consider the authority record as a kind of gateway drug to scholarship.
Equally, a registry made of many voices offers a history of the effort that went in to creating those records. It can serve as a forum that promotes consensus around a work but also tracks the ebb and flow of the debate. This process of documenting and moderating that debate, and of crafting tools that can be used by experts and amateurs alike, is what Wikipedia’s history offers.

This is a piece that was part of the New Museum’s New Show
, in New York City. I found much of the show problematic and this piece especially so.
It’s a ten-foot tall green screen
. Green screens – or more accurately chroma key screens – are used in the film and television. The blurb on the wall was some pretty breathless text talking about deconstructed realities and and questions of authenticity but what really floored me was when I discovered that they had printed the piece out on an ink-jet printer.
Who knew you could print green screens in an ink jet printer? You could do this at home. You could do this at home and go out and paste them around the city. Imagine the fun you could have if you lined 5th Avenue, in New York, with green screens and told people.
Besides being a kind of playful tool for exploration wouldn’t that also be a more interesting way to talk about the issues raised by chroma keys?
This is hardly a direct analog to what I’ve been talking about today but I want to leave you with the story so that you think about what the equivalent ink-jet printer is for authority records.
Authority records aren't going away, nor should they, but out of necessity they squeeze most of the life out of the stories and the context that surround that which is being classified.
So what I am suggesting is that you start to investigate ways to use the authority record as a means for inviting communities of enthusiasts in to your process.
Not only would this create an avenue for participation but it can open up the space for you to better use your knowledge and understanding to provide a kind of "bias knob" for those works you do consider important and to breath life back in to them using the magic of language and story-telling. To help situate them in the wildflower garden of history.

Thanks for listening. This is a difficult subject to talk about without either getting ranty or painting everything with an even broader brush than I already have and there are lots of influences and rabbit holes that I chased while preparing for this presentation that were left out for one reason or another.
If you’re curious, I’ve been keeping a list of bookmarks over here and I would encourage you to take a look.

Thanks again!
This blog post is full of links.
#mw2011In/The/Sky
So, all but a year ago I went to Museums and the Web and did a workshop about machine tags. In the working code
part of things I spent a lot of time describing how Flickr shoe-horned support for complex machine tag queries in to Vespa, the internal document index at Yahoo. Vespa looks and feels a lot like Solr so I outlined how you'd go about implementing it there. I also spent time explaining how we (finally) managed to implement machine tag hierarchies but noted that we had to go back to using MySQL because there was no way to support both complex queries and hierarchies in the same index.
As I write this I am sitting on red-eye, full of people farting and doing yoga in the aisles, heading back to Museums and the Web and poking at the newly released Solr 3.1. Looking over the sample schema file I discovered the addition of a path hierarchy tokenizer field type and idly wondered...what if.
The answer is yes!
From - Sat Apr 02 01:51:22 2011 Message-ID: IN-A-CHAIR-IN-THE-SKY Date: Sat, 02 Apr 2011 01:51:18 -0700 From: Aaron Straup Cope MIME-Version: 1.0 To: [redacted] Subject: ask and you shall receive Content-Type: text/plain; charset=ISO-8859-1; format=flowed Content-Transfer-Encoding: 7bit So, it's a ways from being done and a long way from being complete but: 47 ->curl 'http://localhost:8985/solr/flickr/select?q=*:*&indent=on' <?xml version="1.0" encoding="UTF-8"?> <response> <result name="response" numFound="2" start="0"> <doc> <int name="accuracy">16</int> <str name="details">{"farm": 6, "secret": "c88b65daab", "server": "5289", "ownername": "Drewber66", "title": ""}</str> <int name="license">0</int> <str name="location">43.643822,-79.51661</str> <long name="photo_id">5310424703</long> <str name="photo_owner">48825531@N03</str> <str name="place">Canada/CA/ON/Etobicoke/Sunnylea</str> <arr name="tags"><str/></arr> <str name="timezone">America/Toronto</str> <arr name="woeids"><int>55855779</int><int>479</int><int>2344922</int> <int>23424775</int></arr> </doc> <doc> <int name="accuracy">13</int> <str name="details">{"farm": 6, "secret": "575a3b5fe9", "server": "5202", "ownername": "MtHoodMeadows", "title": "Sunny Day"}</str> <int name="license">0</int> <str name="location">45.367313,-121.697745</str> <long name="photo_id">5310415361</long> <str name="photo_owner">37366645@N02</str> <str name="place">United States/Oregon/Hood River County</str> <arr name="tags"><str>snow</str><str>ski</str><str>oregon</str> <str>mthood</str><str>snowboard</str><str>mthoodmeadows</str></arr> <str name="timezone">America/Los_Angeles</str> <arr name="woeids"><int>2347596</int><int>23424977</int></arr> </doc> </result> </response> What's interesting is the "place" field, tokenized as apath hierarchy(so is timezone) which is a new thing in Solr 3.1: http://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters#solr.PathHierarchyTokenizerFactory Which means you can suddenly do shit like this: 50 ->curl 'http://localhost:8985/solr/flickr/select?q=place:*Etobicoke&indent=on' <?xml version="1.0" encoding="UTF-8"?> <response> <result name="response" numFound="1" start="0"> <doc> <int name="accuracy">16</int> <str name="details">{"farm": 6, "secret": "c88b65daab", "server": "5289", "ownername": "Drewber66", "title": ""}</str> <int name="license">0</int> <str name="location">43.643822,-79.51661</str> <long name="photo_id">5310424703</long> <str name="photo_owner">48825531@N03</str> <str name="place">Canada/CA/ON/Etobicoke/Sunnylea</str> <arr name="tags"><str/></arr> <str name="timezone">America/Toronto</str> <arr name="woeids"><int>55855779</int><int>479</int><int>2344922</int> <int>23424775</int></arr> </doc> </result> </response> Which means — I'm pretty sure — you can suddenly do *both* machine tags and machine tag hierachies in Solr: 54 ->curl 'http://localhost:8985/solr/flickr/select?q=*:*&indent=on&facet=on&facet.field=place&rows=0' <?xml version="1.0" encoding="UTF-8"?> <response> <result name="response" numFound="2" start="0"/> <lst name="facet_counts"> <lst name="facet_queries"/> <lst name="facet_fields"> <lst name="place"> <int name="Canada">1</int> <int name="Canada/CA">1</int> <int name="Canada/CA/ON">1</int> <int name="Canada/CA/ON/Etobicoke">1</int> <int name="Canada/CA/ON/Etobicoke/Sunnylea">1</int> <int name="United States">1</int> <int name="United States/Oregon">1</int> <int name="United States/Oregon/Hood River County">1</int> </lst> </lst> <lst name="facet_dates"/> <lst name="facet_ranges"/> </lst> </response> And yes, it works with more than two records: 66 ->curl 'http://localhost:8985/solr/flickr/select?q=*:*&indent=on&facet=on&facet.field=place&rows=0' <?xml version="1.0" encoding="UTF-8"?> <response> <result name="response" numFound="100" start="0"/> <lst name="facet_counts"> <lst name="facet_queries"/> <lst name="facet_fields"> <lst name="place"> <int name="United States">73</int> <int name="United States/US">24</int> <int name="United States/Texas">17</int> <int name="United States/Texas/Plano">17</int> <int name="United States/Oregon">10</int> <int name="United States/Oregon/Hood River County">10</int> <int name="United States/Indiana">7</int> <int name="Canada">5</int> <int name="United States/US/MA">5</int> <int name="United States/Indiana/Indianapolis">4</int> <int name="United States/Pennsylvania">4</int> <int name="United States/Pennsylvania/Philadelphia">4</int> <!-- and so on --> Which is kind of god damn hot. Also, I AM IN THE MOTHERFUCKING SKY.
This blog post is full of links.
#sky