I am (still) lazy and (still) don't like reloading webpages
Four years ago, I wr^H^H^H... I mean, said to Myles:
I like The Guardian, in part because they've always been so quick to grok what the interweb could do for them. For example, during the 2002 World Cup they added live-blogging of the matches which, despite being so brain-dead obvious, no one else was doing at the time. I am a fair-weather tball fan so I couldn't tell you whether the people they've gotten to do the job are
qualifiedbut they are about four million times more fun than anything else out there.Four years ago I was hanging out in IRC channels and made an idle threat to write a scaper-bot to suck down the commentary and post new bits as they arrived. So the other morning I wrote something just like that which I can run from the command-line.
And later:
There is also the part where I've never seen anyone use the current crop of weblogging applications to chunk out individual updates as separate posts. So far, all writers do is keep a running commentary in a glorified text file (or single post). This is not an insurmountable problem technically and I will go out on a limb and predict that within a year someone will draft a spec for µblogging to address this issue.
It's pretty obvious that there's a demand for live-blogging; as in any event that people want to follow, in real-time, with a story and a little more personality than a text message containing canned highlights. I'm not saying that the Guardian should charge money to deliver live-blogging outside their website, only that I might actually pay for it if they did. I would not pay for plain-old access to their website. This has also been my problem with the subscription model going back to Salon's initial pay-wall. Just give me the fucking data to either play with myself or to plug in to a clever third party application.
Like an IM thingy.
In fairness, the last four years have seen The Guardian not only rid themselves of commas in their URLs but also publish a pretty great API that allows you to search for the live-blogging happening around the day's World Cup matches. But still there's no way to get the bloody updates — you know, the stuff being said — all by itself.
This seems especially crazy in a world that has finally caught up to the reality of a network that is mostly on and phones that can walk and chew gum at the same time. It's true that The Guardian have created mobile versions of their live-blogging pages but they are finicky to use, don't auto-refresh and most importantly don't generate any kind of system-level notifications for new updates.
So somewhere over the Midwest last week I wrote yet-another scraper-bot. A scraper-bot and a relay machine if you're being fussy about it. The bot asks The Guardian API for the URLs of the current day's World Cup live-blogging posts, fetches the updates and shoves them in to a JSON file. The relay machine reads the JSON file, keeps track of posts its already seen and displays those it hasn't.
Originally, I imagined the relay bot would be running on my phone using the built-in notifications framework. As it happens, the individual posts are way too long for the tiny little notifications windows (stick that in your micro-social-twitter-pie (hole) and smoke it...) so I switched to sending the updates over XMPP (specifically GTalk) since IM somehow remains the best class of software for dealing with this kind of thing. Also, I have an IM client on my — drumroll — phone, so I can keep track of what's going whether I'm sitting at my desk or out walking around.
It looks like this:
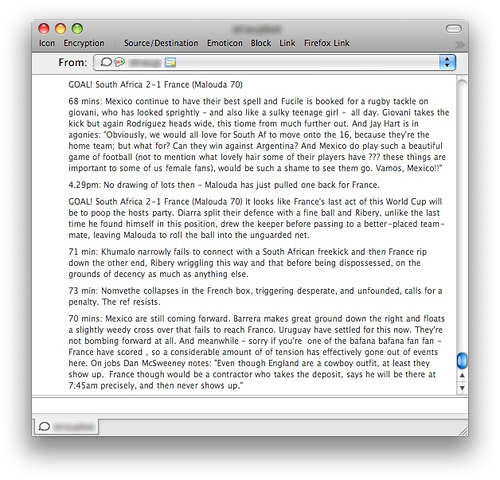
Hey look... updates from two different webpages that I don't need to reload! Did I mention that I'm lazy?
The JSON file of all updates is over here if you want to find something interesting to do with it. Be aware, though, that it's still very much a moving target. Each update contains a hash of the text which is a rough 80/20 way to track and filter out posts that have already been seen but it is not uncommon for the writers to update individual entries, whether it's at the end of the match or during the game. There's also no pruning of older matches so the file itself just keeps growing; I may fix that soon. If you want to run your copy of the bots, or submit patches, all the source code is available on the Github.
With any luck, The Guardian will just publish their own cleaned-up love notes... I mean, updates file and then the whole thing will be moot. In the meantime, here's to small futures loosely joined with stuff (and things).
This blog post is full of links.
#olewoedb
Or: A present for Gary, on his first day at his new cube. Or: Myles is my God page.
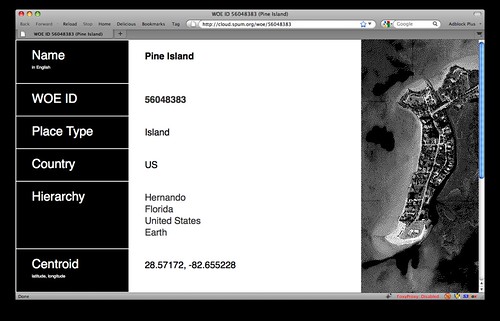
Pretty soon after we started working with Where On Earth (WOE) at Flickr I began to make God tools
to introspect all the data. This became especially important when we had to follow the twisty guts of the reverse geocoding process but they were also a good way to simply get a handle on the volume of places and relationships indexed in WOE.
Mostly, they were held together with duct tape and bubblegum; only the barest of functionality designed to just work in my browser with the shortest amount of development time. Which is to say they worked (which is to say I couldn't have done my job without them) but they were butt ugly and clunky. Every once in a while Kellan would try to convince me that we should release a public version on Flickr proper but between the (at the time) questions about opening up the data and the amount of work involved in cleaning up my kludge-tastic webpages it was an idea that never faired well against all the other things we were doing.

In the time between then and now, Flickr quietly released the Places info pages (/places/info/{WOEID}), Yahoo! released most of WOE dataset under a Creative Commons license (some day, I will a compelling reason why they decided to rename it GeoPlanet
...) and I spent some time taking all that data and putting it in Solr where it could be poked at and noodled around in. Sort of like the Flickr God
pages but without, you know, the pages.
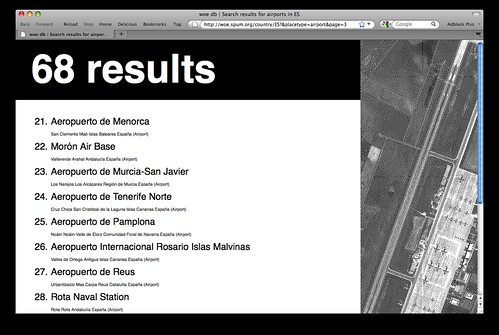
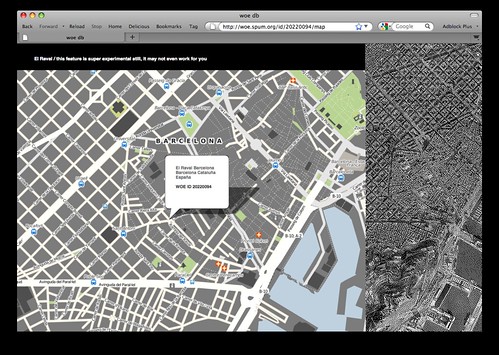
So, over the weekend I finished up the first pass at the woedb, a searchable and linkable index of every single Where On Earth (WOE) ID published. Each WOE lists basic information like name and place type, as well as child locations and adjacencies and all the various aliases for that place. You know... linked data
. As of this writing, there are about 5.5 million entries.
Here's what the about page says:
- A page for every WOE ID.
- A page for every country (and their airports).
- Search.
- Search nearby.
- Surprises.
- Works in progress.
Did I mention that I like airports?
There are still a few more ways to facet the data that I'd like to add and lots of little things (like auto-magic geolocation detection for the nearby pages and search by geohash) but this seems like a good place to set it down for a while and find its legs. I've already found some brainfarts in the way the data's been indexed so I will probably re-feed everything in the next couple of weeks and maybe even fold in Flickr tags to the list of things that can be used to search for places.
And the things. With all the stuff.
I will probably put the code that runs the site on Github shortly if anyone wants to help out or add features. Short term, I'm going to turn my attention back to the plumbing for a bit and make sure that the site is properly wired to work with Solr 1.4 and also use it as a stomping ground to test all the new geo-hawtness in Solr 1.5. Until then, enjoy!
This blog post is full of links.
#woedbfirst your addressbook / now your dictionary
Sometime back in December, of last year, I took a moment to imagine what the next four months might look like. To give you some background the long version is long and the short version is full of drama. Back then it all looked like giant clouds of fuck-you looming on the horizon. They were. Four months later I was sitting in a hotel lobby, in Denver, with Bruce Wyman and joked that if I ever caught up on my sleep I could file the entire experience under War Stories
and generally get on with it.
Being attacked by life sucks. Being attacked by life when you have a whole stack of obligations that you not simply agreed to but genuinely want to do sucks the suck (so to speak). In my case the entire time leading up to April was haunted by the knowledge that I had been accepted to write and present a paper at Museums and the Web on the practice of curation, in a world where the Internet exists. There are few topics guaranteed to get people in the museum world worked up and generally crazy in the head than a discussion of the role and meaning of curation and if I was going to poke them in the eye I was very concious of wanting to do it with a suitably sharp object rather than, say, a worn down pencil nub. Which is to say, paraphrasing Russell Davies and Jack Schulze: It's worth not being shit.
I am super grateful to Jennifer Trant and David Bearman, the conference organizers, for being so patient while I struggled to write the thing. Normally, when I do these things, the paper follows the slides which act as a kind of strong outline where each slide should be able to serve as jumping off point to discuss (or argue) a given point over drinks. As it happened, the paper took on a life of its own and the next trick became how take what had become a very large surface area and craft it in to a very small pony.
The paper, titled Buckets and Vessels, is available to read on the Museums and Web site and I've included my slides below but the basic outline/argument was the following:
- The practice, if not the art, of curation is alive and well.
- No one is storming the gates because there is, in fact, a giant party happening outside the gates.
- Galleries (at Flickr), the tyranny of motivation and
little big pictures
. - The vanishing economics and general muddling of roles in a captial-A art world that includes the Internet.
- Bookmarking time and
betting on the future
But really, the core of the argument centers around the fourth point and I don't think I've done a very good job articulating that yet.
The really short version is this: It's not that people don't care or value what curators are doing. It's that they have no idea what most of them are saying. There exists, for good reasons or bad, a language of specialization that prevents most people from participating in a dialogue about art or the ideas it fosters. Which is hardly the same as not wanting to participate: People are not suddenly self-identifying as curators. Rather, what we are seeing is a growth of tools being made available to allow people to exercise a curatorial muscle many people never knew existed, even if the results don’t always look like something we’re used to.
It may seem a bit crass to point it out but the roles that have typically distinguished curators from critics and both from, say, docents has largely been economic, specifically the means of production and distribution. It's not like docents don't have stories to tell but rather there's been an historical deficit of fast, cheap and out-of-control (read: easy) way to share those ideas beyond the small and focused groups who visit them in museums. Enter the web which isn't necessarily going to Change Everything™ but does afford people the ability to not care so much about what the so-called professionals are doing. The so-called barrier to entry, and all that.
If you think that's crazy-talk I will just point out that there's been a similar collapsing of roles going on between artists, designers and crafts-people for about a decade already. The arts versus crafts debate starts to seem quaint when you see artists designing, well, designer bags and Threadless (which is really just old-school printmaking by any other name) making money hand over fist.
Which raises the question: How much is a language of specialization, or an expert discourse, really just a language of scarcity? And how did we ever let the arts and humanities get to this point?
I remember being told that there are something like 50, 000 fine arts graduates (I don't remember if that number included both undergrad and graduate degrees) every year in North America alone. I'm not suggesting that there should be fewer, on principle, but it does raise another question: What exactly are all those people supposed to do? Compete for jobs, apparently.
In Canada we've had the Canada Council and various other arts funding institutions, that help to support artists and promote their work, for a couple generations and, on measure, we're better for it. At the same time, it's been a bit of breeding ground for an especially noxious culture of entitlement and a fiercely competitive environment because there's still not enough money to go around. I'm not going to suggest that we call the project a failure but maybe this is one of those places where we need to put a sign-post that reads Well, this didn't work
and try something new.
I got excited about the web because it seemed like the perfect end-run around the backwaters of the art world and the gallery system and the relentless networking. I did not get in to this racket because I was particularly enamoured of computer programming but because I was excited by the web and the opportunities it affords people to make things and share them. If the goal of fostering the arts — and an intellectual pursuit around them — means anything I'm pretty sure it doesn't mean buying into a system and a practice of active obfuscation and exclusion as a means of economic security.
But I only had twenty minutes so I only managed a kind of fumbled approximation of all that. The slides and verbatim notes from the talk are included below in a separate blog post.

Oh yeah, and day before that I did a 3-hour theory-and-practice workshop about machine tags, which was super fun. The timing turned out to be good as Twitter announced annotations about 45 minutes before I started the workshop and Facebook announced all their OpenGraph stuff, which is really just machine tags embedded in <meta> tags, a few days later.
The workshop itself was chunked in to three parts: theory, practice and ponies (or sometimes robots, depending on my mood).
The theory
part was really a discussion about why tagging was interesting and successful where other more formal ontologies and classification systems, not to mention the dream of the semantic web, have only ever gotten far enough off the ground to make a dull thud when they come crashing back down to Earth. If you know the boundaries of your problem in advance then a comprehensive (read: existential) methodology is awesome but if you've got a project like Flickr where the edges are always shifting then it turns out to be both an enormous technical burden but, more importantly, a conceptual buzz-kill.
This turns out to be just as true when you're talking about all-thing geo and place related. Language is, after all, magic and naming things (tagging, if you want) is still the thing that gives our lives a little bit of texture.
The practice
part was what machine tags looked like at Flickr which really meant a (long) short history of how search was architected and a catalog of hacks and dirty little tricks we employed to make it work and find our own use for things. Machine tags at Flickr were always a margins-of-the-day project which meant that they needed to be as thin a layer on top of the way tagging already worked, from both a conceptual and user-interface perspective as well as the technical backend required to support it. That meant a few mistakes got made along the way and some pretty basic mechanisms for discovery took longer to put in place than maybe they should have (to their credit Twitter seem to be addressing those problems up front with their annotations stuff) but despite all of that we managed to make a little bit of magic, I think.

The third part was a bit sparse, mostly because of time constraints (and me talking too much about all the other stuff) but the short version is: Robots a-la astrotagging (or noticin.gs) to read and write machine tags automatically and basically everything Matt Biddulph said about concordance in his Mobile Social Location
talk. I know there's a lot of talk these days, in the geo, about the need for a single open database of places. It's not so much that I think it's a bad idea but rather that I don't think it will ever happen and would likely get stuck in the quick sand of auestions of authority and interpretation. I would sooner see more efforts like the Y! Geo Concordance APIs where providers are able to continue to make claims about their ground truth but still provide a series of small bridges to and from other data sources. As a standalone API, the Y! Geo stuff is only of limited use and I would prefer to see Yahoo! and other data providers simply offer data dumps of their concordances that so everyone can figure out how best to make sense of the connections for themselves.
In the social media space, a few people have focused on the fact that this data is put in place to enable sites to be added to Facebook’s social graph. However there is little reason why other social networking services couldn’t also read the same markup as a way to add those web sites to their social graph.
To some people that's naive crazy-talk on the grounds that those lists are the magic secret sauce for a lot of businesses. All I can say to that is: Good luck. If you think your business is going to succeed because of a locked box full of data instead of an actual service that does something with all that data, I'm guessing you're in it for the short game or to drink everyone else's milkshake. Either way, that's not a world I want to live in.
There weren't any notes, per se, for the workshop. This is all stuff I could talk about for hours on end so the slides were really mostly a crutch to keep my comments organized in something like a coherent arc. There is however a 21-page hand out (complete with a 15-page reading list) available as a PDF file and the slides themselves are over here as plain-old web pages (because there are about 200 slides and that just makes for a monster too big for SlideShare).

And the day before all of that was the Wikimedia@MW2010 workshop, an all-day session with invited guests from the museum world and Wikipedia community (and me) to talk about ways that the two communities could work together better. It was an odd event, probably not as productive as people had hoped for but I think that it gave the participants a better measure of each other's concerns and tolerances. On the one hand you had curators and museum professionals genuinely wanting to collaborate but probably being seen as a bit naive and condescending, telling the young hooligans how it needs to be done, in the face of everything Wikipedia has already accomplished. On the other, the Wikipedians were frankly down right creepy sounding as though everything were just pristine fields of raw data to be hoovered up by the enormous and inevitable maw of their collective hive-mind, somewhat divorced from the idea that there's a whole world of grey between outright edit-wars and even-keeled articles cum authority files.
At the beginning of the workshop we all went around and did introductions and talked about our areas of interest. Since I neither work in a museum or am an active Wikipedian, I figured I would talk about possible stress points:
- Communities as a single point of failure — If Flickr went away tomorrow I would still have copies of all my photos and all the metadata but I there is still no way to preserve the community and the relationships in a way that they could continue to exist as anything more than snapshots of the past. They would be frozen in time. Blaine's been trying to work out some ways to address this problem but the thing about federated-anything has always been that it tends to treat indivudal sites on the web as little more than interchangeable buckets and vessels (I think the technical term is portal but I dislike that word only slightly less than I do webinar) of
content
rather than places of meaning that people pour their heart and soul in to precisely because they are defined by editorial constraints. There is also the part where people still don't think of themselves as URIs; those of us who actually manage to self-identify with our websites are still few and far between. Maybe that will change over time and god know the portal-weeines are trying to draw a straight line between that idea and brand-loyalty but I don't think we're anywhere close yet. - The risk of Wikipedia becoming a gravity-well for links and ideas — First of all, this isn't a Wikipedia-specific problem but their size and impact helps to demonstrate the point. I love Wikipedia and think the work they've done is hugely important but I also don't want them to become a single source of truth anymore than, say, Google. To their credit they have a whole series of checks in place to prevent that from happening but to the extent that they want their project to be an actual reference and more than just a catalog of links to other sites there is always going to be the potential for them to become a giant single conceptual point of failure. This isn't so much Wikipedia's problem as a natural human failure to put all of our eggs in one basket but maybe it's not something they need to encourage either.
One of the last machine tags extras
integrations I worked on at Flickr was adding support for a bunch of train and subway systems. I really really wanted to add support for the MTA, the subway system in New York City, but they still don't have a single page for each station that I can link to. A really good example of an agency that does is BART in San Francisco; they have Places
style pages for all the ... places, in their network. Someone suggested that maybe we could just link to the Wikipedia pages for individual subway stations in New York (or London or Berlin and so on). That would have been easy enough and there's no question that the Wikipedia page would, in most cases, be more interesting but that seemed somehow counter-productive. The point of the machine tags extras stuff was to demonstrate that it was possible to all hold hands without necessarily asking people to give up their control of or authority around a thing's meaning.
Which is an interesting prism to look at the Facebook OpenGraph stuff through. I am one of the two or three people left to sign up for a Facebook account so maybe I'm talking shit, but I don't think so. From where I sit, it looks like they're trying to do to the dictionary — the notional arbiters of meaning that we use as anchor points in our lives — what they've done to the addressbook: Namely, recognize it as the gravity well that it is and build a better one (see also: the address book is still the center of everything) than has ever been done before assuming the rest will just follow naturally. Then again, that was also AOL's dream.

Since then, I've been mostly sleeping.
This blog post is full of links.
#mw2010buckets and vessels

Three years after the fact (it is now 2013 as I write this) it is interesting to me that this talk was very much the germ for two others that followed a year later. The first was the gossip begets genealogy talk at NACIS which pulled even harder on the idea that the characteristics governing the roles enjoyed by artists and designers and craftspeople had in fact completely collapsed, and how a similar confusion was playing itself out in the world of cartography. The second thing to fall out of this one was the Unfinished Histories talk delivered at Museums and the Web the following year. At the very end of this talk I offered what I thought of as a sort of throw-away comment. That if the people I was speaking to thought that the pinnacle of their acheivements as scholars and experts was the authority record then they were about to be eaten by robots
. I spent most of the next year thinking about that idea.
This blog post is full of links.
#bucketsareas of / you are here
I’ve never been one to name my cameras, but this one? She seems like a Stella.
I went to WhereCamp on Saturday and had a grand time. I didn't do a panel of my own because I was already feeling a bit manic and wasn't sure I would be able to lead a simple train of thought let alone a room full of people. But when Brandon Martin-Anderson opened his geo visualizations
session up to the crowd my hand shot up and I showed people some of the stuff I've been working on, so far, in the margins of 2010.
The lesson, Myles, is not to bother whipping up a presentation in Keynote but simply to create a new set on Flickr since you're just going to end up using someone else's laptop (thanks again, Brady) because, despite the fact that we all live in the future now, there are still two things we can't get right: automated soap dispensers and hardware dongles for external displays...
I started by describing (it's really hard, it turns out, to talk about stuff while you're fighting off the urge to throw your laptop across the room) a map I'd seen, taped to the door of a store, walking to the studio the day before. The map was a highly stylized contour of the greater
Mission area topped with Mickey Mouse ears ballparking the Duboce Triangle neighbourhood and the area east of Civic Center. In the center a single point representing the store itself, kind of like the Trouble Coffee pirate map:
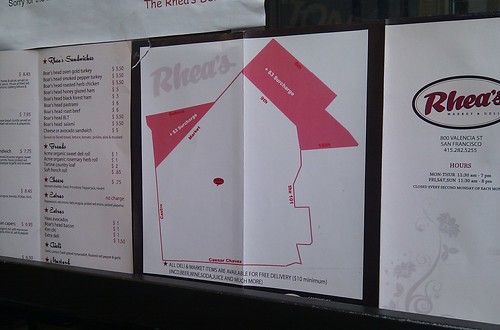
I love this map. I love that the map shows the location of the store relative to the neighbourhood it lives in but then, literally, leaves the rest up to the person using the map turning the whole thing in to a bit of an adventure. Go to the corner of Market and Castro then head towards Bernal Hill. If you hit the 101, turn around because you've gone to far. Welcome to the Mission: Tell us what you saw.
I wondered what the people in Duboce Triangle had ever done to warrant a three-dollar surcharge on everything but this is San Francisco where you learn to suspend your disbelief about these kinds of things.
It was later pointed out to me that it is, actually, just a delivery map. But who cares. It's awesome! I want more maps like this. It is enough to know that something exists within a larger context without necessarily belabouring the point or getting lost in the details. I've spent the last five years mostly thinking about photos and some of the ways that photos can play nicely with maps and I kind of wish we'd stumbled on this sort of thing sooner. Now that there are shapefiles for all (most) of the neighbourhoods assigned to a photo it's possible to produce a variation on the delivery map, above, like this:
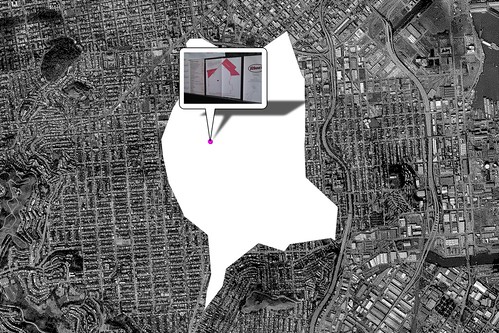
It's not perfect, by any means, but I enjoy the way the neighbourhood frames and (sort of) focuses attention on the photo. I like that it leaves space for the viewer to imagine a space around the photo, literally and figuratively; a sort of enforced exercise in design fiction.
These are some of the same ideas I was poking at when I spent a weekend making a series of maps called I See DOTS. The maps themselves are just a standard satellite view covered in dots. The dots are geotagged photos tagged with terms pulled from the flickr.places.tagsForPlaces API method; the method returns the top 100 tags for a given WOE ID, in this case San Francisco.
In isolation they're kind of pretty but not terribly compelling. But when I looked at series of four different renderings, each produced with the same dots and the same bounding box but a different zoom level it started to get more interesting:
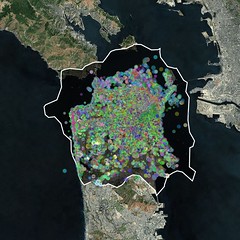
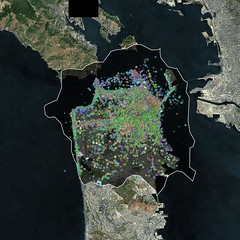
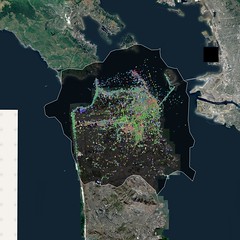
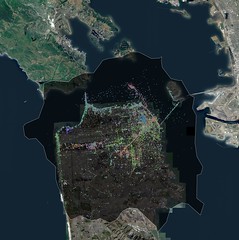
The lower zoom levels (12 or 13, I think) required fewer pixels to draw so all the dots get smushed up together. You can see a few patterns like all the photos tagged oceanbeach down along the Great Highway but otherwise it's basically pea soup. When you zoom in though you start to see a very different picture as the distribution of photos starts to snap to the grid of the city or, more likely, a tourist's (and people who live in the Mission) city.
There are a lot of criticisms you could make about an approach like this not least of which is the lack of all those other tags (and photos) that didn't make it in to the top 100 tags list. I don't really care about that part though. What I'd like to do with this work is something along the lines of Brett Camper's 8-bit maps. I'd like to generate tiles where the dots expand and contract as you zoom in and out. I'd like to generate map tiles that give you that same dizzy feeling you get when you look down at a city at night, from an airplane. In some ways I don't even care about the street level tiles. I do but we've spent so long fussing over the relentless details in cartography that we've sort of forgotten what things (should) look like at a distance.
We don't usually think of the bird's eye view as having a skyline
but maybe it should.
And, still, after all this time I talked again about the Flickr shapefiles. I heard, second-hand, that Twitter has not only been generating their own shapefiles from geotagged tweets but that they're going to release them publicly too. This is super exciting because it means there will be more raw stuff and tools with which to make maps, even if they look weird or aren't something you'd want to rely on for bombing your enemies. Maps are having their F-64 moment, right now, which is important and wonderful but I don't think anyone really wants to live in a world with an infinite depth of field. It's an appealing idea but then something like the Hipstamatic comes along and we all get irrationally weak in the knees, all over again.
During his presentation at Where 2.0 Jesper Anderson talked about the fuzzy nature of distance and place. For example, if a particular neighbourhood intersects the line between point A and point B the total distance
may not be constant. For some people the distance is n + the y miles it takes the circumnavigate, and avoid, that neighbourhood. For others it's x + the y minutes they'll spend lingering in its gravity well. It's true that these sorts of affordances make it difficult to, say, process credit card transactions. At a certain point you have to draw some boundaries if you want to accomplish a specific task. But if that were really all we can do with computers and the Internet (and maps) I don't think we'd have invested as much time as we have looking under the rugs and scratching at the edges of things.
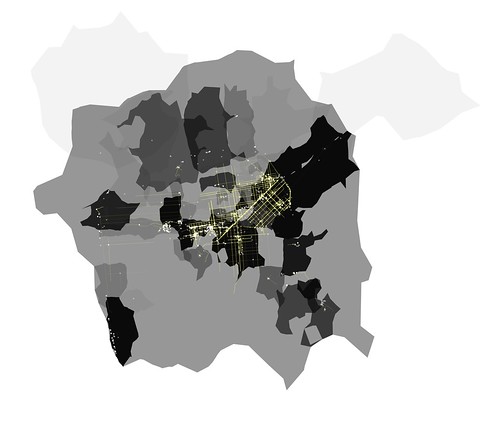
I finished up the talk by showing some of the more recent experiments with pirate maps and pirate walks. The picture above is a pirate map of all of Heather's photos geotagged in San Francisco drawn on top of the shape for the nearest WOE ID that each photo was taken in. (Each shape is drawn multiple times with a very low opacity so frequent visits mean some neighbourhoods are darker than others. It's not the most sophisticated approach, but it's a start.) I like it because the geography starts to act not unlike the way cell-painted backgrounds do in what Wikipedia affectionately refers to as traditional animation
: When it works it's like having your own personal soundtrack walking down the street and not someone else's canned jingle jack-hammering itself in to your soul.
When it works...
This blog post is full of links.
#youarehere