
you are here / maybe

Sometimes people ask me what the deal is with Gowanus Heights. Gowanus Heights began after I spent 15 minutes one day poking around Everyblock try to figure which neighbourhood the block I live on belongs to. I still don't know.
The experience looked something like this:
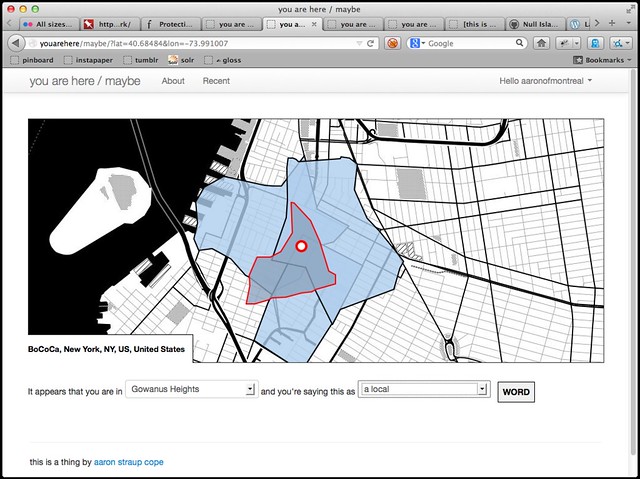
These are not Everyblock's neighbourhood shapes. They are the alpha shapes derived from geotagged photos on Flickr, plus one for Gowanus Heights. You know, in case you ever found yourself wondering: What exactly is BoCoCa?
We really do live at the overlap of four neighbourhoods so I was less bothered by the mess of choices than by apparent inability — or unwillingness — of Everyblock to pick one. Or to let me pick one.
At the time I started joking with people that I was just going to create a new neighborhood since apparently we live in an instance of China Meiville's breach
. The running candidates were Cobble Gardens
and Cobblewanus
. Over drinks with a long-time neighbourhood local it was correctly pointed out that Gowanus Heights
is more in line with the history of naming conventions in New York City.
Thus was it ever. At least if I have my way.
This is a thing I wrote, a couple years ago:
Never mind so-called disputed places (Kashmir, the West Bank, Cyprus, etc.) all neighbourhoods are "disputed" around the edges. (This is often true of localities, as well.)
For example, the rough consensus in San Francisco is that Delores street is the dividing line between the Mission and Noe Valley. That said there are those people who may live on the one side of the line and very much believe themselves to be living on the "other". Our experience has been that there are few better ways to pick a fight than to tell someone what neighbourhood they are in (and being wrong).
There is also the problem where the data simply doesn't exist yet or it is just old and dusty, sometimes wrong, and often plain weird : "Manhattan Valley", anyone?
This is further compounded by the lack of ideas/tools/infrastructure for reflecting changes (both socially and politically) but, ultimately, those are both somewhat tangential.
This blog post is really about those tools I talked about a million years ago.
Last week Kellan and I were bemoaning the still generally shit state of reverse-geocoding in 2013. Eventually we wondered why there wasn't a tool (an app
to use the lingo of the young folk) which would use their magic-sky-device's GPS capability and ask people where they were at that moment and collected that data for further processing, like generating new alpha-style shapefiles.
Kellan's been talking about it as being like a game and I've been saying the thing is essentially geocorrections
as a service. So I started trying to build it. It's called you are here. It's is very much a work in progress and there is nothing public to play with yet but you can follow along on Github.
Conceptually there are four big pieces:
-
Matt Biddulph's flickrgeocoder-java daemon.
Matt built a happy little httpony around the Java Topology Suite and GeoTools libraries which do point in polygon queries. That's all it does. When he first wrote it the code was hard-coded to use the second release of the Flickr alpha shapes. Since then he's updated it to accept an arbitrary list of shapefiles on the command line. That's super-good and I'll talk about it more, in a moment. My tiny contribution so far has been a patch to enable CORS headers when sending back results. Eventually I hope to add support for GeoJSON results but I am still not much of a Java weenie so it might take a few false starts before that's done.
-
A web application (the you are here part) that queries the reverse geocoder and records people's choice.
That's the piece I've been working on for the last week. This is the part that let's you say a given spot (a latitude and a longitude) is contained by a given place with a unique ID. Currently that means a Where on Earth (or WOE) ID but the important thing to remember is that you could use any dataset with enough points to create a polygon. David Blackman's just released geoplanet-concordance for mapping Geonames IDs and WOE IDs feels important that way. Don't forget that the Flickr alpha shapes were derived from a twisty maze of overlapping squares.
-
Exporting the data as publicly available and liberally licensed dumps (or eventually pubsub-style broadcast streams).
I've been trying to imagine what this might look like.
Good enough
might just be daily dumps written to a GitHub repository. Or maybe something something pubsub-ish in nature. It wouldn't be that hard to add support for pubsubhubbub- style notitifications over HTTP but in between the other moments I've been wondering what sort of Redis pubsub-as-a-service type services there are, preferably ones where the barrier to use for people subscribing is minimal-to-none. Which means: Not forcing people to sign up for yet-another account or have to be billed to use it. The jury is still out on that one. -
Processing that data and feeding it back into Matt's reverse-geocoding tool.
This could mean generating new alpha shapes, beta shapes or even gamma shapes. Or all of them. The point is to make shapes for all the things. Most of the things that Eric Fischer has been making in the last few years are derived from nothing more than an enormous bag of dots, so we are bounded only by our imagination.
Depending in how you're counting things there's a fifth item or a non-trivial aspect of the second item which I haven't mentioned yet. It's not clear to me. Specifically whether the code should try to be smart and apply suitable rankings to future queries for a user. As it is, the site is more about data collection than data crunching; more about you answering questions rather than answering questions for you. It doesn't necessarily need to be that way but it's been a handy constraint (simply trusting whatever Matt's thing says) since I only have an hour or so in the mornings to work on this.
On the other hand if, as I've been imagining, I add an API to the site that other services could use (privatesquare is an obvious candidate) then there's rapidly diminishing value in forcing people to say No, this is what I meant!
Unless the whole thing is framed as a game, as Kellan suggests.
Maybe? Maybe not?
If this all sounds suspiciously like what we were saying when we talked about corrections and the alpha shapes and reverse-geocoding at Flickr that's because it is. I apologize that we never got that out the door. It was clear as day to me but it was also interrupted by all the other things going on and then I forfeited my right to do anything about it by leaving. I have no idea what or how they're thinking about this problem these days but the fact that the geo corrections API methods have been updated, without warning, to require that you include a foursquare ID suggests they're doing ... something?
I mentioned Matt's thing. I made a little run.sh script to hide the usual rain-dancing required to start a Java thing so all you need to do is pass the port number you want your server to listen on and the list of shapes to query. Like this:
# Start one server (on port 5000) to query only neighbourhoods $>you are in flickrgeocoder-java, in the corner is a factory$> run.sh 5000 \ src/main/resources/ ... /flickr_shapes_neighbourhoods/OGRGeoJSON.shp \ src/main/resources/ ... /gowanus_heights/gowanus-heights.shp # Start a second server (on port 9000) to query localities $>you are in flickrgeocoder-java, in the corner is an abstraction$> run.sh 9000 \ src/main/resources/ ... /flickr_shapes_localities/OGRGeoJSON.shp
See the way we're able to squirt in the shapefile for Gowanus Heights? That allows us to easily mix-and-match data sources. Most of the examples in this blog post assume the Flickr shapefiles but you could use anything, really. I am still waiting for Matt to accept my patch to have Null Island included with the default distribution but you could just as easily imagine using Pleiades as a data source or La Lengua (Gowanus Heights' sister neighbourhood) or Miquel Hudin and Wendy MacNaughton's Mini Tenders. That's quite good.
It's not entirely clear to me if running multiple servers is the correct approach. My gut tells me it is because each daemon is constrained largely by the amount of RAM necessary to load everything in to memory (plus operating costs) which means you could distribute the different place types across a variety of machines and pool them as needed. Given that the application code talks to the daemons over HTTP it would be easy enough to stick a Squid machine (or equivalent) were that ever necessary.
It is also helpful in narrowing the scope of the query. Which is a nice separation of concerns that follows the model that we used at Flickr:
- A hierarchy can be derived independent of the query to convert a lat,lon to place ID (in this case a WOE ID)
- If I can't figure out what neighbourhood you're in because you're in the back woods of Idaho I should at least be able to figure out that you're in Idaho or if not that then the US. Hence the filtering of query by place type.
As of this writing the site still only queries neighbourhoods but you can override that by passing a filter parameter. For example... New Jersey?
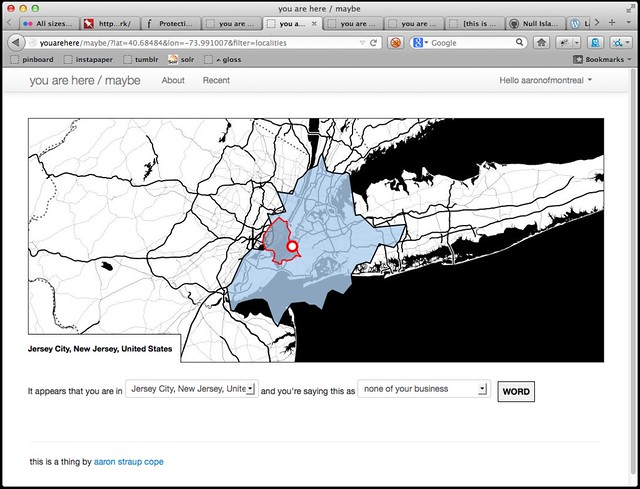
The Flickr data is weird. Given how large and floppy metropolitan areas often are the site should probably be using the donut hole
shapes for localities where they're available. It's also important to remember that the underlying dataset we were working with routinely told us stuff like Brooklyn is a county
so whatcha gonna do? The point is not whether the data is correct. The point is that there's a way to express an opinion about it.
Because I am pretty sure this is not Lomita Park.
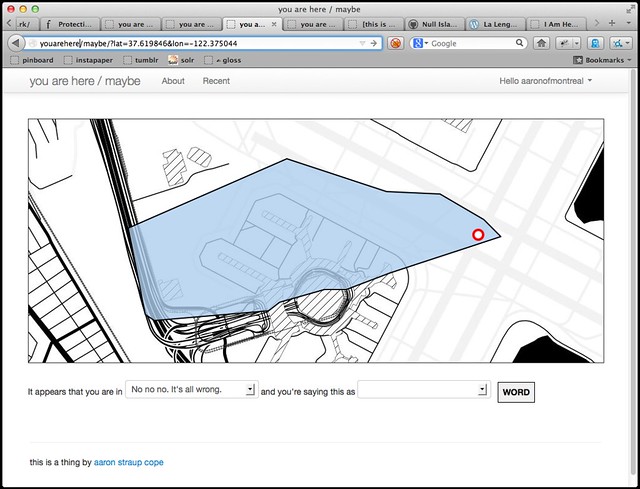
You can also indicate a perspective when you say where a place is. Valid options are local
and tourist
and none of your business
.
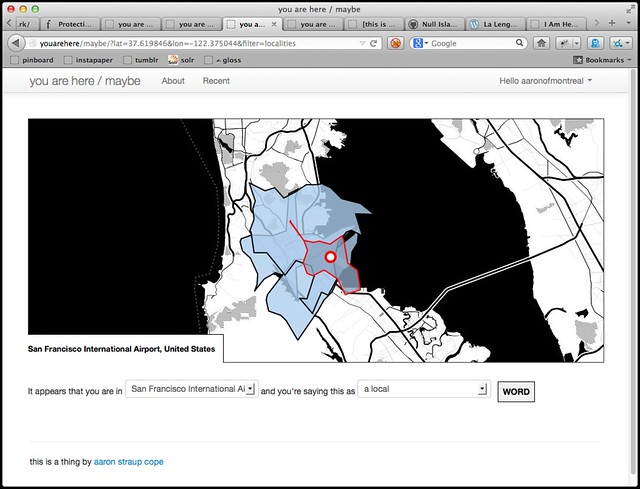
Or ?filter=countries. It turns out that people like to take pictures on boats in the US.
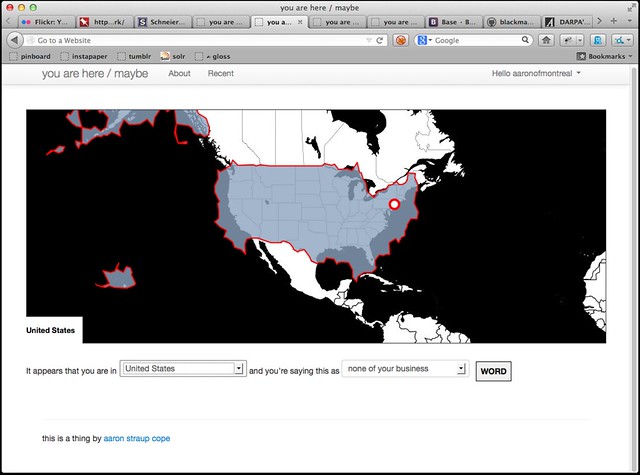
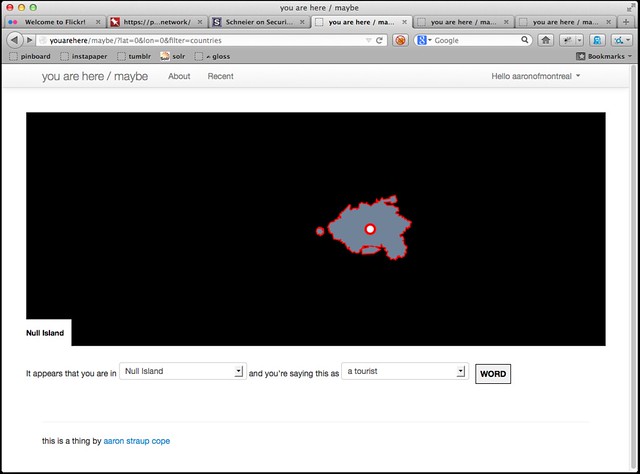
Speaking of which, did I mention Null Island?
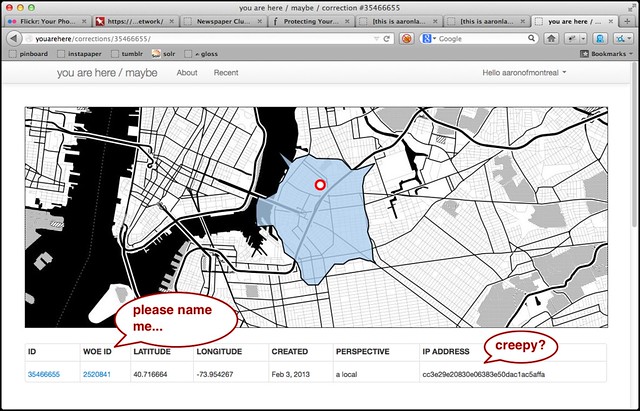
It's still a ways from being public-ready thing but it basically works. There are permalinks for every correction (lovingly hand-crafted with artisanal integers, of course) and list views by date and WOE ID and, if enabled, by user.
One of the goals — the primary goal — is to release all the data publicly because [insert rant about geo data here]. It is equal parts sad-making and hate-making that we're all still stuck suffering the lack of a comprehensive and open dataset for places. It's 2013 and maybe we should be focusing on features instead of subtle variations on the theme of data/vendor lock-in? Crazy, I know.
The site uses the Twitter API as a single-sign-on provider mostly just as a barrier to prevent bored-in-a-meeting style abuse but also to let people consuming the data make their own judgements based on the number of corrections a user has made, their distribution over space and time and so on. The question I'm having is not whether to include their actual Twitter usernames in the data dumps but whether to include an obfuscated identifier. An encrypted hash of their Twitter username, for example.
This is what the site says about the subject, right now:
The idea is for all of this data to released publicly under as liberal a license (for the purposes of re-use) as is not-annoying.
Data dumps will not contain your (Twitter) username but might contain an obfuscated user identifier. This is so that people consuming the data can make better informed decisions about which corrections to trust. Or not. I am still working through the ways in which that might get creepy.
The point is not to promote a naked Facebook-esque mirror world but to find an acceptable place where privacy interests and transparency can exist. That might not be possible and if that's the case then a user's privacy will take precedence.
The same issues apply to the question of recording and displaying IP addresses. The goal in both cases is to provide some hooks for someone processing the data to gauge the value of a person's contribution. It's a sideways kind of signal-noise throttling since it assumes that anyone/thing that is too noisy will just be dropped in the floor.
In the meantime I've add feature flags so that the recording of IP addresses can be disabled entirely and I may just hash them all (with a site-specific secret) on their way in to the database.
I'll get something up and running in public shortly. I would like for this to be more than a prototype. Whether people use you are here or not the larger project is important. As Kellan points out we have a 100mil+ people carrying GPS device in their pockets and we have to buy expensive proprietary data to find out about the shape of where we live
.
We should fix that.
Update (April 2013): youarehere.spum.org went live on April 01, 2013. It's still not polished the way it should be (and notably lacks a public API still) but it works. Data dumps are being collected and republished on Github at https://github.com/straup/youarehere-data.
This blog post is full of links.
#youarehere