Any sufficiently advanced correlation is indistinguishable from causation

Here is a lightly-annotated collection of articles and papers, on or about the question of inference, that have struck a chord recently. And some drawings and pictures thrown in for good measure.
- Data ordering attacks, Light Blue Touchpaper
Most deep neural networks are trained by stochastic gradient descent. Now "stochastic" is a fancy Greek word for "random"; it means that the training data are fed into the model in random order. So what happens if the bad guys can cause the order to be not random? You guessed it – all bets are off. Suppose for example a company or a country wanted to have a credit-scoring system that's secretly sexist, but still be able to pretend that its training was actually fair. Well, they could assemble a set of financial data that was representative of the whole population, but start the model's training on ten rich men and ten poor women drawn from that set – then let initialisation bias do the rest of the work. Does this generalise? Indeed it does. Previously, people had assumed that in order to poison a model or introduce backdoors, you needed to add adversarial samples to the training data. Our latest paper shows that's not necessary at all. If an adversary can manipulate the order in which batches of training data are presented to the model, they can undermine both its integrity (by poisoning it) and its availability (by causing training to be less effective, or take longer). This is quite general across models that use stochastic gradient descent.
This was interesting to me for two reasons: 1) It is the kind of generic toolkit that could/should be applied to any number of interactive contexts in any number of museums 2) It highlights the lack of capacity across the sector to be able to take something like this and adapt it to its own specific needs. I expect that, inside of five years, at least one large institution will blow 6 or 7 figures hiring an external firm to implement this as a one-off which is... a missed opportunity, really.

- An update on the UMN affair, Linux Weekly News
One final lesson that one might be tempted to take is that the kernel is running a terrible risk of malicious patches inserted by actors with rather more skill and resources than the UMN researchers have shown. That could be, but the simple truth of the matter is that regular kernel developers continue to insert bugs at such a rate that there should be little need for malicious actors to add more. The 5.11 kernel, released in February, has accumulated 2,281 fixes in stable updates through 5.11.17. If one makes the (overly simplistic) assumption that each fix corrects one original 5.11 patch, then 16% of the patches that went into 5.11 have turned out (so far) to be buggy. That is not much better than the rate for the UMN patches.So perhaps that's the real lesson to take from this whole experience: the speed of the kernel process is one of its best attributes, and we all depend on it to get features as quickly as possible. But that pace may be incompatible with serious patch review and low numbers of bugs overall. For a while, we might see things slow down a little bit as maintainers feel the need to more closely scrutinize changes, especially those coming from new developers. But if we cannot institutionalize a more careful process, we will continue to see a lot of bugs and it will not really matter whether they were inserted intentionally or not.
- How image search works at Dropbox, Dropbox
- Generative Models as a Robust Alternative for Image Classification: Progress and Challenges, An Ju
- ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision, Google AI Blog
All three papers are a reminder that almost all machine learning work is predicated on disproving the adage that past performance is not an indicator of future success, which... well, you know.
- Enhancing Photorealism Enhancement, Intel Labs
This is very impressive work but the phrase “It greens the parched grass and hills in Grand Theft Auto’s (GTA) California” sort of sums it up. It’s clear that GTA is a MacGuffin for the underlying work but it betrays a disservice to the material quality of the GTA’s aesthetics and the relentless focus on “style transfers” suggests that it’s just pumpkin spice lattes all the way down...
During the time that I was at Stamen we had started to talk about a bias knob
for data visualizations. This was largely a rhetorical device since no one was quite sure what the technology to make such a thing possible would be. It is nice to see the use of machine-learning in the work that GSD is doing framed in similar terms, that it is a fast and efficient tool for applying pressures to different parts of a dataset and seeing what happens rather than a magic veil
of truth. These are some of the things I wrote about this at the time:
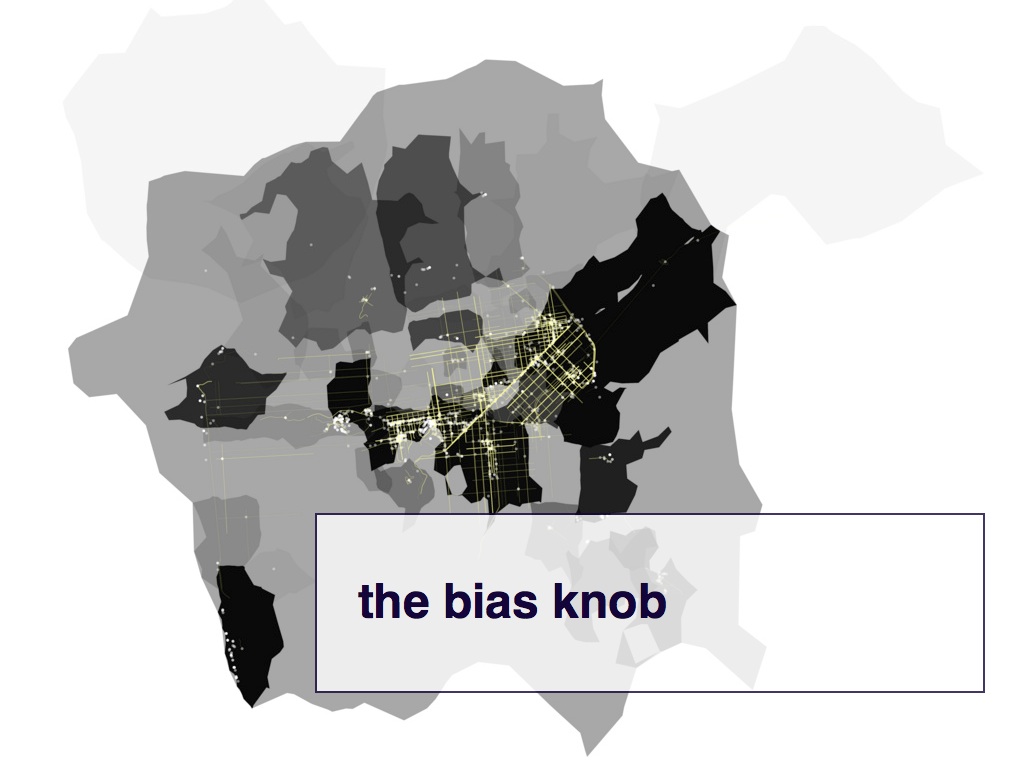
One of the things I like about this image is that you can clearly see that Fort Funston, the place where H. goes to walk her dogs, is part of her San Francisco. You can see this not because of the roads on the beach; there are none. You can see this because the photos cause the neighbourhood around the beach to materialize.
In a lot of generative art works, and in game design, there is the idea of a "physics knob" that you can use to adjust the relationships between different objects and the environment in which they exist. I've always tried to imagine what it would mean to have a "bias knob" that you could use to affect how cause and effect, or in this case maps, are displayed.
we need / MOAR dragons
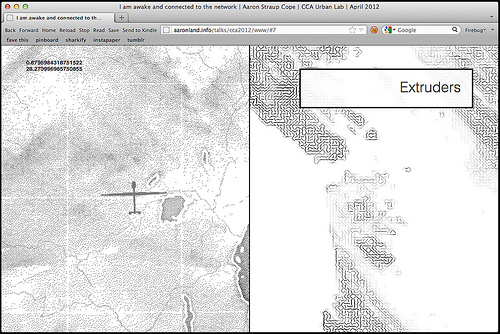
In the past I've talked about producing and treating maps the same way you might work with a bolt of fabric but maybe it's also like making pasta where the data (and the choice of data) acts as a kind of extruder shaping the noodles. I don't really want to get lost in bad kitchen metaphors so I'm going to stop there and instead leave you with the image of the raw data acting as a kind of screen through which the squishy mass of history, of time and place, is passed to create a map.
I am awake and connected to the network

What search-by-color and other algorithmic cataloging points to is the need to develop an iconography, or a colophon, to indicate machine bias. To design and create language and conventions that convey the properties of the “extruder” that a dataset has been shaped by.
a colophon for bias

- Image "Cloaking" for Personal Privacy, SAND Lab
The SAND Lab at University of Chicago has developed Fawkes1, an algorithm and software tool (running locally on your computer) that gives individuals the ability to limit how unknown third parties can track them by building facial recognition models out of their publicly available photos. At a high level, Fawkes "poisons" models that try to learn what you look like, by putting hidden changes into your photos, and using them as Trojan horses to deliver that poison to any facial recognition models of you. Fawkes takes your personal images and makes tiny, pixel-level changes that are invisible to the human eye, in a process we call image cloaking. You can then use these "cloaked" photos as you normally would, sharing them on social media, sending them to friends, printing them or displaying them on digital devices, the same way you would any other photo. The difference, however, is that if and when someone tries to use these photos to build a facial recognition model, "cloaked" images will teach the model an highly distorted version of what makes you look like you. The cloak effect is not easily detectable by humans or machines and will not cause errors in model training. However, when someone tries to identify you by presenting an unaltered, "uncloaked" image of you (e.g. a photo taken in public) to the model, the model will fail to recognize you.
Which bookends nicely with the paper on data ordering attacks.

This blog post is full of links.
#correlation