
4up

Dan said something the other day that I've said every way but actually saying it because I still don't want to believe it. He said: Ah, Flickr, Feb 2004 - Oct 2013, we had a good run but clearly it’s time for us to go our separate ways, we just want different things.
I haven't posted anything that meaningfully looks like a photo to Flickr since the launch of the Biggr (sic) redesign in May of this year. Almost as soon as the redesign went live I taught Parallel Flickr to upload photos to itself but not necessarily to Flickr. In that way the software learned all the tricks of Privatesquare which has always been a kind of looking glass archive, capturing the activity to be archived but only maybe sending in on to the nominal source or service to be archived. Pushing photo uploads through that kind of looking glass necessitated a bunch of interesting architecture and software decisions but I'll save that discussion for another blog post.
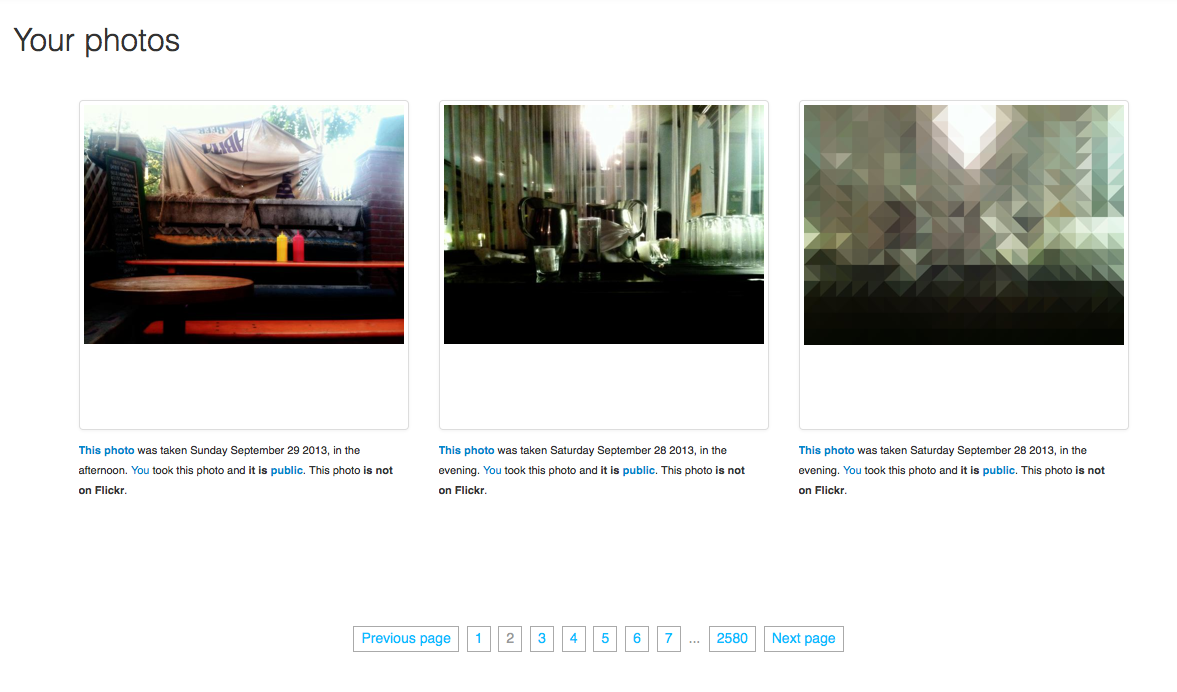
I also taught Parallel Flickr to generate stylized — obfuscated, really — thumbnails of uploads that it controlled and those would be posted to Flickr (and promptly archived in turn because Parallel Flickr uses the real-time Flickr PuSH feeds to archive photos). This was an experiment to try and use Flickr as a kind of signal fire to let people know that I was taking photos, just over there
. In Twitter's early days Kellan used to talk a lot about how Flickr might use it as a notification system for photo uploads. I don't know if his suggestions would have worked at the time but I've always rememebered them and so, in 2013, I wondered if Flickr itself might be used as that signaling mechanism (for things I'd uploaded to Parallel Flickr). In the end people just hated all the pixelated photos and wondered what I was on about this time.
Around the time of the big groups redesign, where every group was assigned a canned thumbnail with little bearing to reality and less to the group itself, I more or less gave up. Any photos not already public were replaced with a placeholder which continues to be a rich source of hilarity and unexpected consequences for me and Parallel Flickr but that's also a story for another time. I haven't done much since then. I still favourite photos occassionally and Parallel Flickr dutifully backs them up. I have a 2004-2013 in-the-style-of-Heather last photo
sitting somewhere on my laptop but I haven't posted it and I don't know if I will.

Although it remains a real possibility (because you know, Yahoo) unless Yahoo manages to completely poison the well I try to remind myself that Flickr is (was?) a photo-sharing website and that we encouraged people to share photos with each other. Purging all those photos and links out of anger doesn't really square with everything we tried to build over the years. So for now they stay. Mostly, though, I am not ready to believe that it's over.
That's the sad-making part of this blog post. I'm not really interested in a longer discussion of all the ways it hurts to use the site these days. I am heartbroken to watch everything we did being dismantled but we all left and might all be dead if we'd stayed any longer than we did so this is what happened instead. And I don't honestly know what happens next. Talk is cheap but photo-sharing, done right, is still hard.

I've been joking with people that my Little Printer is my new photo-sharing service. I send myself (and M.) photos and tape the print-outs to the wall and watch as they curl and yellow and slowly vanish. In all the talk about ephemera, these days, there is something pleasant in the tangible finality of thermal paper. Recently, mroth and I joked about building SnapHop
, a service that lets you upload photos which are only visible in a year's time. I was going to build that on the flight home but I still have a day job trying to re-open a museum so there are actual limits to how much time I can spend with all this crap.
None of the upload-to-self stuff in Parallel Flickr that I've talked about is enabled by default either but I might set aside a couple of days to document its current state and list all the gotchas and just push it out of the nest.
Somewhere in all of this, Mike Migurski decided to archive his Pinterest account as a book. He wrote the code to read a CSV dump of all his Pinterest posts and then automagically figure out how to place the optimal number of (up to 4) photos on a single page and then generate a PDF file of the whole thing. Mike's Pinterest account was pretty epic so printing a single image per page would have resulted in a book too large to be bound and too expensive to imagine. They are lovely books and so one day I asked Mike if he would share the source code with me. And he did.

It was, he pointed out, very much specific to his needs and to the vagueries of the Pinterest API but I've been poking at it since then and with Mike's blessing have released the code on Github under the name 4up
. It's called 4up because I needed a quick, pithy name for the then-private repo and it's sort of catchy and because the code usually manages to lay things out four to a page.
The first task was figure out what bits of the Pinterest API and resultant CSV file were actually necessary to use the code with another source. As of this writing I've managed to pare it down to the following:
full_img,id,meta
For example, this is what one row in a CSV file full of Flickr photos might look like:
http://farm1.staticflickr.com/1/132429_cb520f81ce.jpg,132429,"{""og:description"": ""Untitled-1, by mickey1 (2004)"", ""pinterestapp:source"": ""http://www.flickr.com/photos/44124351339@N01/132429""}"
If you're looking carefully at the example above and wondering why the various properties are named the way they are it's only because this is still early days and I've been more concerned with identifying the bits that can be removed rather than what things should or should not be named. So og:description and pinterestapp:source it is, for now.
Then, thanks to Mike, all you need to do to generate a big honking PDF file is:
$> python ./layout.py -d data/flickr-photos-2005.csv
And then you'll end up with something like this:
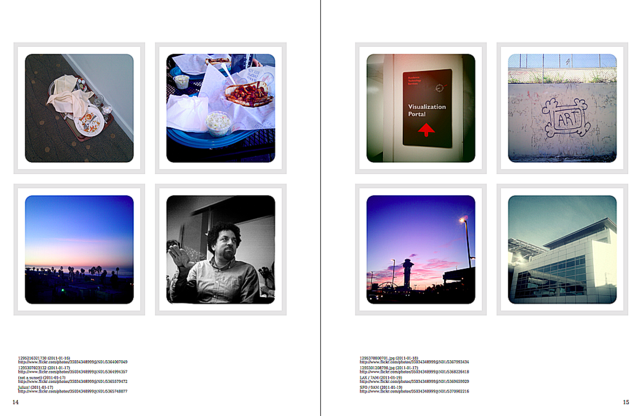
That's about where things stand today. The repository has helper scripts for generating 4up "compliant" CSV files for a user's photos or favourited photos on Flickr:
$> python ./flickr/4up-photos.py -c flickr.cfg -u me -o ../data
The scripts will dump all the photos in to CSV files grouped by year uploaded or year faved. There are still lots of limitations to the code including the part where the Flickr helper tools are all written to use old-skool Flickr Auth API token instead of the newer OAuth credentials so if someone wants to send a pull request to deal with that I'd be grateful. The code itself can be found over here:
Update: hugovk has already sent in a patch to make the Flickr scripts work with the new OAuth API bits. Yay!
Beyond that there are all sorts of details and edge cases to solve: How to manage really long books without running out of memory or splitting them in to multiple books or being clever about page numbers if they are. The default number of pages for a book is 240 but you can configure that manually although a book of Flickr photos 300 pages long caused the machine I'm working to throw a hissy fit and stop working. Or splitting books based on overall file size rather than page number (notwithstanding the running out of memory problem) because services like Lulu won't let you work with individual files that are larger than 2GB.

The good news is that there is (not super user-friendly yet) code which should be able to create hot Mike-style books from any source that can be squeezed in to the CSV format described above. I've been focussing on Flickr photos and have yet to send anything out to be printed yet so there may be a few revisions left before its anything like a general purpose tool but I think this is a nice happy-making antidote to all that other gloomy stuff I started with.
This was going to be the part where I mentioned that I would absolutely consider uploading these "books" to the Internet Archive, along the same lines of the PDF versions of this weblog that I talked about in the papernet.css blog post. I was going to mention this because the problem with doing that is that any book of Flickr photos will likely contain lots of not-public photos and there are really only binary public/invisible privacy controls on things uploaded to the Archive.
If the Archive implemented a 70-year rule (or 40, or 100) that would allow me to upload things which would remain private until a certain date — a kind of SnapHop
for cultural heritage even — I wouldn't think twice about sharing my Flickr photos. As it is now it's all or nothing and that feels like a problem people in the so-called memory business need to think about.

Having already gone through my Flickr photos and redacted
all the private and friends-family photos it's actually not a problem I have anymore but it's another example of an idea I touched on, in the Quantified Selfies talk, last summer, that there needs to be: an explicit contract where ... the Library promises to preserve the permissions model in the present in exchange for a person gifting that present to the future.
In the meantime, books. Or photo albums. Or small tools for ...uh, artisanal photo-sharing? Or something like that.
This blog post is full of links.
#4up