Personal Digitial Archiving 2012

I had the pleasure of speaking at this year's Personal Digital Archiving conference, held at the Internet Archive. I did a talk about parallel-flickr and this is what I said, only just finishing in advance of the worst of all possible live demo failures: Flickr having an outage...

Hi, my name is Aaron. I have no particular affiliation other than myself, these days.
I was at Flickr for about a thousand years (or 2004 through 2009) as part of the engineering team. After that I spent a couple years at Stamen Design, here in the city, as part of the nerd squad and appointed myself Director of Inappropriate Project Names in the process.
I left the studio at the end of 2011 and am currently a Man of Leisure enjoying a little bit of long-overdue rest. So far, this has included small side projects like "cloning" Flickr and is part of the reason I am here today.
I was reminded, during Brewster's comments this morning, that before all of this I was also involved in an early community-based photo-sharing site called the Mirror Project. I am ashamed to admit that the only place it exists on the Internet anymore is somewhere in this building as part of the Wayback Machine.
Update: I am pleased to say that on August 27, 2012 we relaunched The Mirror Project! See Heather Champ's blog post for details. Yay!!

Before we get started I'd like to mention that this is the only URL in the entire talk. It points to an appendix which contains references and links to everything I'm going to mention today, and I will show it again at the end of the presentation.

The other thing I want to say is that this talk takes the worst case scenario not as a given but as a useful starting point for the exercise of thiking about what to do next.
The worst case scenario of course being: What if Flickr disappeared tomorrow?
Maciej Ceglowski and Jason Scott, who are both speaking here at the conference, have each had formative experiences with Flickr's parent company, Yahoo, that give them every right to think I am being hopelessly naive when I say that I don't actually think that anything bad is about to happen to Flickr.
I can live with that. There's a lot of anxious talk these days though little of it caused by anything that Flickr itself is doing.
Mostly it's due to the perception that Yahoo is fumbling around, and fumbling around in public, for purpose in the world and the sense that the upper layers of management are completely divorced from any reality that the rest of us understand or experience. And what it means for Flickr to be beholden to them.
Even if Yahoo decides to "sunset" Flickr it won't happen with the speed or the casual disregard with which they shut down Geocities or Delicious. If it ever happens it will be a long and slow and agonizing process but that is not something we have to worry about today.
Which means this is the perfect time and space to think about what we do if the worst ever does come to pass.

Here's the crazy thing about Flickr, though: For all the mistakes that we made along the way we got enough right that, for all intents and purposes, no one ever felt the need to backup their photos. We enjoyed a crazy amount of trust from our users in part because we took the responsibility of that trust seriously.
So, no one ever thought to backup anything on Flickr. At least until now.
This has led to a lot of teeth-gnashing and finger-pointing and accusations that Flickr is holding people's photos hostage and why doesn't Flickr have one-button export functionality and so on.
My friend and former Flickr colleague Kellan Elliott-McCrea wrote a blog post about this subject last year and in it he talks about the idea of "minimum competence" for social software. In Flickr's case that: "you can get out, via the API, every single piece of information you put into the system."
Which is great if you are comfortable working with APIs. But what if you're not?
We very deliberately chose not to create a Flickr-blessed backup application because we hoped it was an opportunity independent developers would seize. In retrospect, maybe we made the wrong decision.

But back to today. Which means spending a little more time in the past.
In 2005 I started writing a tool to backup my photos and all their metadata. I did not do this because I was worried about the safety of my photos. I did it as much as an intellectual exercise, and a way to become intimate with the Flickr API and to remind myself of the adage that "lots of copies keep things safe".
Being 2005 I tried to do the right thing and adopt all the best practices around XML, the Semantic Web and static, linkable resources. I open sourced all of my code. This is an example of one of the metadata files.
In hindsight this approach had a fatal flaw.

It is incomprehensible gibberish.
Worse, it's hard to do anything with. Not only are the data models overly-complex but all the stricter-than-strict, standards-compliant tools that grew up around them are hard to use.
This is a really important point, especially if we're going to talk about personal archiving.
If I can't stand to look at this stuff seven years later then what hope is there that someone who does not live and breathe the technical details will?
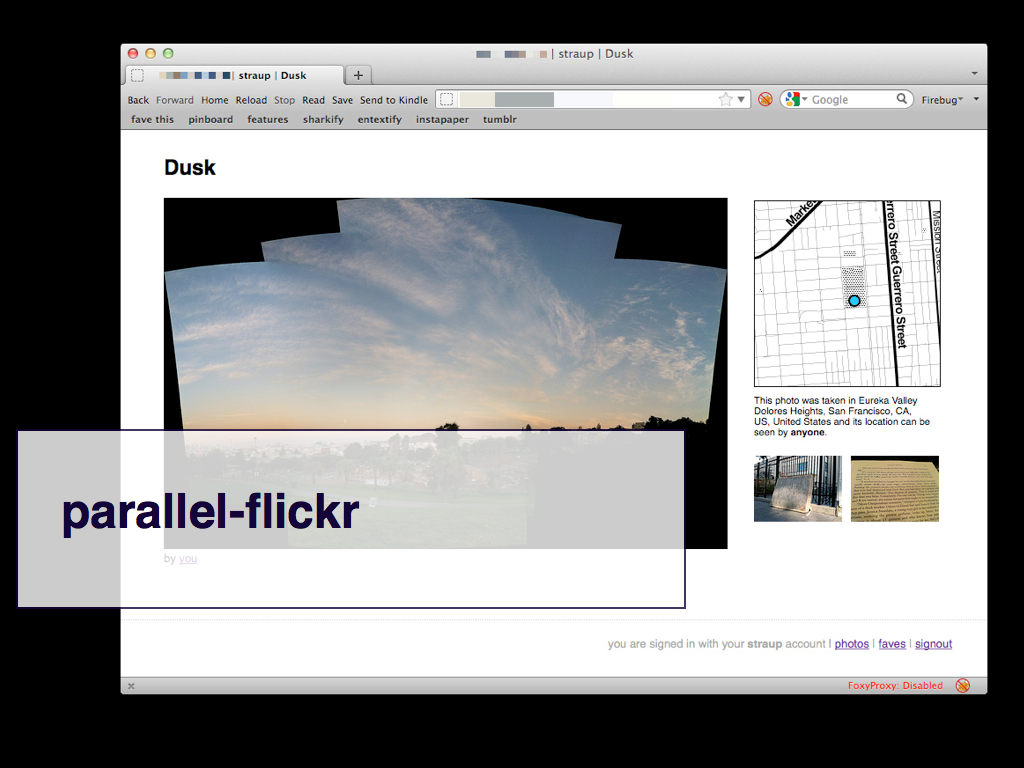
Which brings us to parallel-flickr. Almost.
Fast forward to 2010 and you will find a bunch of ex-Flickr engineers slowly rewriting most of the core libraries and code that we used to build Flickr itself.
The goal was not to rebuild Flickr, the site, but simply to have a set of familiar tool to be able to continue writing web applications in a manner we'd all grown to love.
Around the same time I was trying to figure out what to do about my dusty archive of Flickr photos. I asked myself the question that I asked earlier: If Flickr were to disappear tomorrow what would I do?
I would have all of these photos and all this glorious metadata and no way to actually show, or share, any of it. All of those fancy RDF files may be interesting to robots that have yet to be written but they are a bit of a slap in the face to normal humans.
Having a pretty good idea of how Flickr works under the hood and being involved in a project to rewrite the code that built Flickr it seemed like a logical next step to simply revisit the problem as a website.
Or: parallel-flickr.
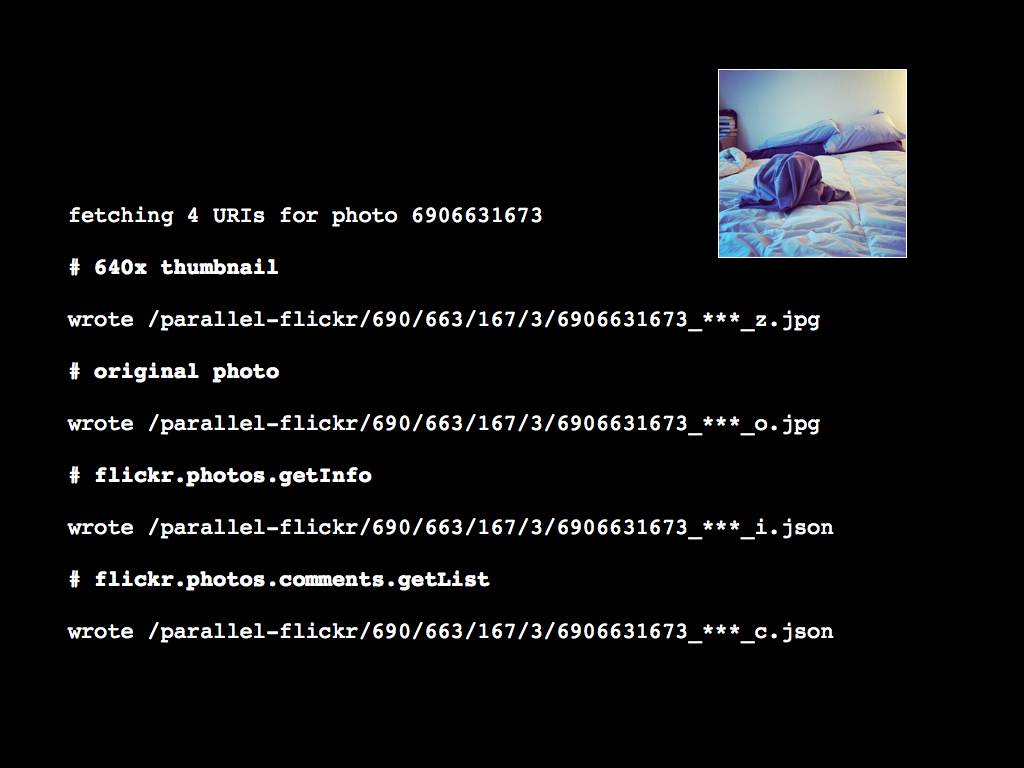
parallel-flickr uses the Flickr API to retrieve the photos and the basic metadata and comments associated with each for one or more users. It also preserves and honours the viewing permissions which is something I'll discuss in detail, shortly.
It stores each one of those files as either an image or a text file in a folder keyed off of the photo ID. Every photo is then imported, and indexed, in a database which is used by the actual website.
You can run a copy of parallel-flickr for just yourself or for you and your 5000 closest friends.

This preserves a logical separation between the archive itself (the files) and the manifestation (the website). But unlike the first time I tried to do this it doesn't do it by sacrificing the manifestation.
And these files are easily transferable and easily manipulated. parallel-flickr already has hooks to use Amazon’s S3 (and by extension the Internet Archive) in place of the local filesystem for storing the files and I’d like to add the ability to sync between the two, regardless of what parallel-flickr is using as its primary file store.
And if worse came to worse, you could always just print this stuff out as an archive of last resort.

parallel-flickr also archives the photos, from other users, that you've faved on Flickr. This has the nice side-effect of creating a sort of fuzzy snapshot not simply of my own photos on Flickr but of my experience on the site.
One of the most important things I've tried to do with parallel-flickr is preserve the URL structure that Flickr itself uses.
Again, if we ask the question "What happens if..." then there are going to be a lot of broken flickr.com URLs out there.
parallel-flickr is not a perfect solution to this problem but if someone can say to their friends "Well, just replace 'flickr.com' with 'mywebsite.com' in all those URLs" then that's a start.
It is at least *something* which is better than nothing which is, by and large, the situation we're in today notwithstanding things like the Wayback Machine.
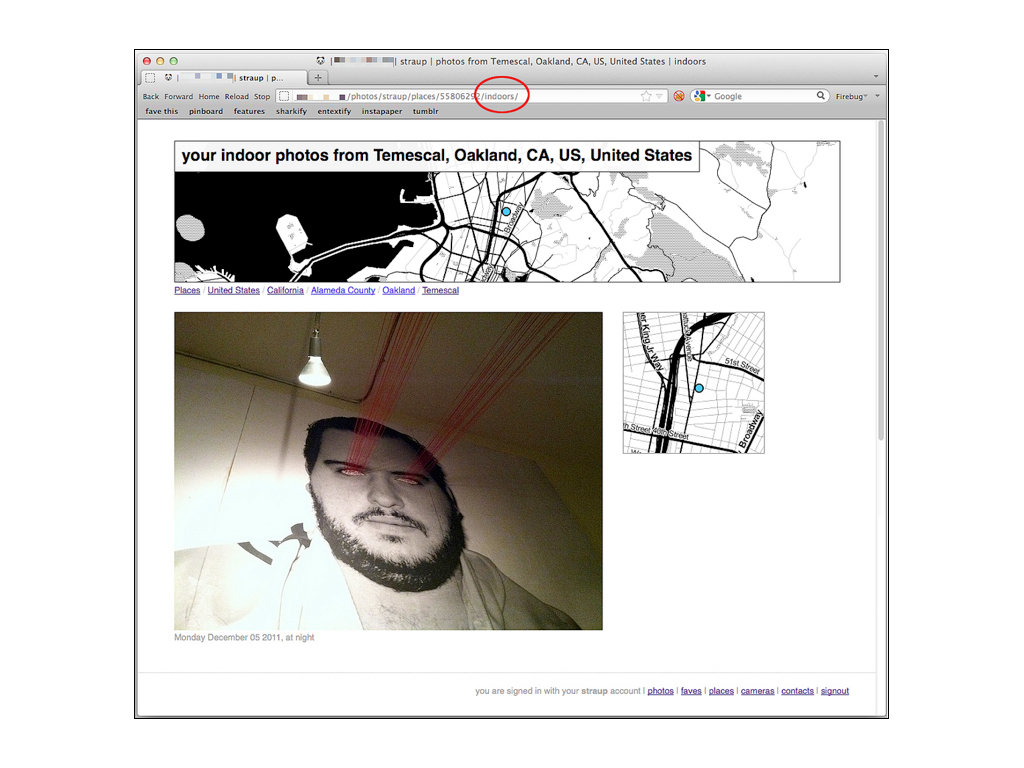
It's also been a place to work on purely experimental features or to develop interfaces for experimental features on Flickr that released but that never made it on to the site itself.
This slide shows a combination of the Flickr "Places" pages but scoped to a single user and then scoped again by the idea of geographic "context". In this case only indoor photos from a particular neighbourhood in Oakland.
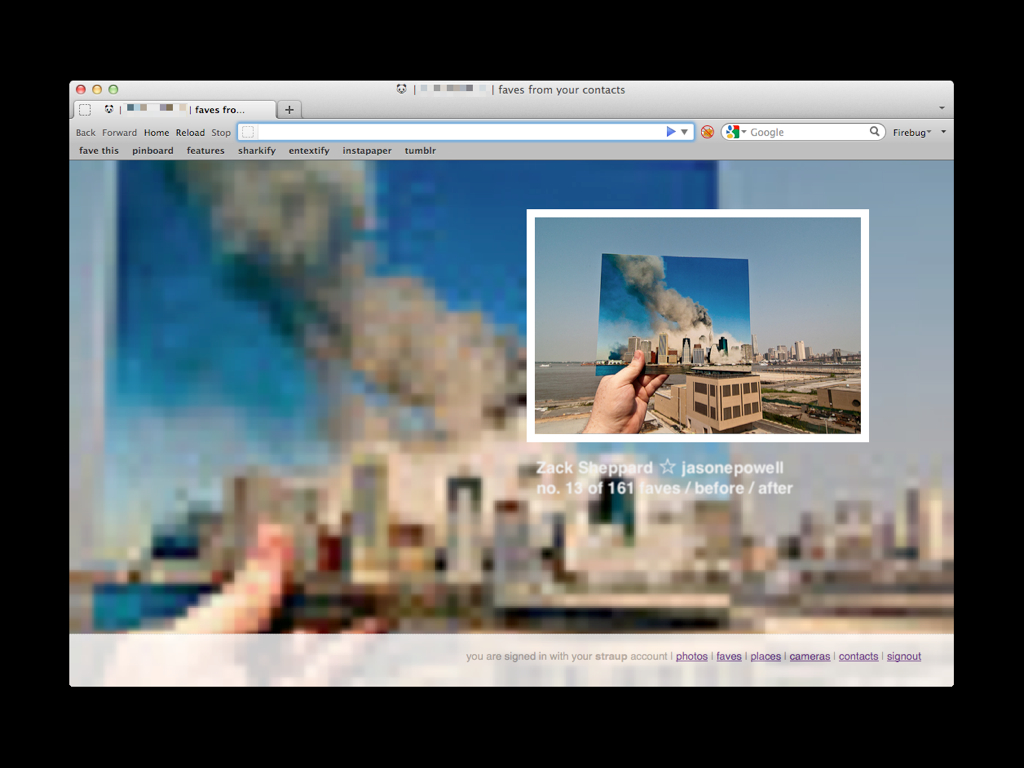
The experimental stuff might also prove useful for archiving. This is a little application I built around the recently released real-time subscription feeds, from Flickr.
This application shows me all the photos that my contacts have faved in real-time but I could just as easily modify it to be notified of my new photos, or updates to my photos, and use that trigger to automatically archive those images.
parallel-flickr is not being run as a public service but is available as open source software, with a BSD license, and is still very much a work in progress.
The site is built to run on nothing more than a standard LAMP stack, the sort of thing you might find on a shared web-hosting service. For the fancier features it requires having a copy of the Solr document index but the actual archiving part works just fine without it.
The label on the tin reads: "It ain't pretty or classy but it works". That sums up the current state of the documentation and the installation process, too, which are still geared towards a technical audience. I would love to make parallel-flickr as simple to use as a "one-button install" but at the moment I've been concentrating on some of the other plumbing.
I'm not going to touch the part about what Git and Github mean for archiving because we don't have time but if you're as interested in the idea as I am please come find me during the conference.

I mentioned that parallel-flickr honours the viewing permissions that you assigned your photos (and any location data) on Flickr.
Another consequence of taking the responsibility of hosting other people's photos seriously is that there are a lot of not-public photos on Flickr.
I know people who've uploaded over 20, 000 photos and I'd wager that a quarter of them, or more, are marked as "private" or "friends and family".
What happens if a person manages to archive all of their photos but then has to go through them by hand to cull the not-public ones? Realistically, nothing happens because people are busy trying to get through the day. Which means that there's a good chance that user will never put those photos back in the Internet. So they're gone. Just like that.
Even if they had a way to automate the process they still don't have any way to restrict who can see those photos once they're no longer on Flickr. So those 5, 000 photos are erased from the Internet. That may not seem like much in isolation but multiply the problem by all of Flickr and the situation starts to look pretty grim.

If you remember nothing else from this talk I hope you remember this slide. Not just because it's funny but because of what it represents.
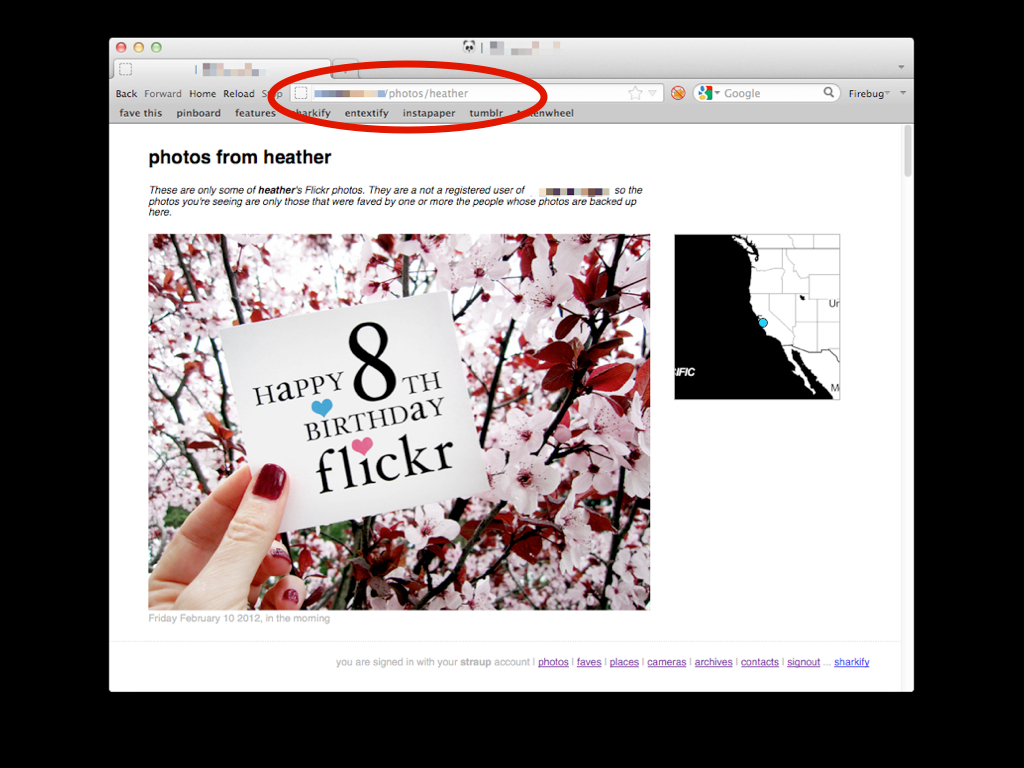
This is a screenshot taken from the list of photos that I've faved.
I actually have the photo in question on my server because when I asked the Flickr API for it the site (Flickr) checked the permissions and everything was kosher. I could, since it's my server, simply go and look at the photo whenever I want.
There are two reasons I'm seeing this placeholder image instead of the actual photo.
First, the photo's metadata and by extension database says: "This is a photo restricted to friends and family".
Second, the photo owner is not a registered user of my copy of parallel-flickr so I don't have any way to know who their contacts are and the permissions they've been granted.
So the code on my server doesn't have any way to know whether or not I am actually allowed to see the photo.
This may seem like a pretty pedantic point but I will simply remind everyone that we've recently had to live through all of our address books being hoovered up by one "social" application after another. And being told that it was "no big deal" or that "privacy is dead, anyway".
Which is madness.
Privacy is genuinely important no matter what people are passing off as industry best practices
. It is doubly important for anything that archives Flickr because a respect for privacy remains core to what the site is about and the ways that people use it.

parallel-flickr is able to do this is by using the Flickr API itself as a single-sign-on service.
If you're not familiar with the concept of single-sign-on you've all seen or experienced it by now. Facebook Connect is a single-sign-on service and it allows a website to ask Facebook to handle the drudgery of authenticating and validating that a user is who they say they are.
As it happens, any API that uses a technique called "delegated authentication" can also be used as a single-sign-on service.
We don't have time to get in to the details of delegated auth but the short version is that it's a way for a user to allow an application to act on their behalf, using a secret token, without having to give up their username and password.
The reason you can use a delegated auth API as a single sign-on service is that in both cases the same question is being asked behind the scenes: Is this user who they say they are?
What that means is that when I log in to parallel-flickr, by way of the Flickr API, then the site (parallel-flickr) now has a "read" token that it can use to fetch and store all of my contacts on Flickr.
Once another user has logged in to my copy of parallel-flickr the site now has a way to test those relationships and the permissions around them to determine who can see a given photo. Because the site now know who a person is on Flickr.
The twist in all of this is that no one really imagined that API endpoints would be used this way. They are all designed with the expectation that an application will perform some sort of action, using a token to identify the user in question. No one thought to add the concept of a plain vanilla validation service to the spec scoped to a token with no particular permissions.
If this seems a little crazy to you that's because it is. This is not a security exploit so much as a lack of imagination on the part of people writing these kinds of specs (and I am partly responsible having been involved in the creation of the Flickr authentication API). Andy Baio's written a really good piece, recently, discussing some of the other problems that have creeped up around delegated authentication and I've included a link to it in the appendix.
I should acknowledge that the whole thing is predicated on users being able to log in to Flickr at least once before disaster were to befall Flickr.
If that doesn't happen then of course some other way of mapping of users to their Flickr accounts would need to happen.
This is the actual hard part of the personal archiving problem: How to deal with authentication and authorization controls defined by a third-party site that may or not exist anymore.
The solution (more like a hack) that I've outlined today should not be confused with a perfect solution but, again, as *something* in a world where we currently have nothing.

This problem is also why parallel-flickr is not the mythical archiving of all of Flickr. Because you can't back up Flickr. Or rather: The only way to back up Flickr with any kind of credibility or ethics is to swallow the thing, whole.
It is the only way to preserve the integrity of what has unfortunately come to be called "the social graph" and what is really a delegation of trust between an individual and a service.
Or you have to reconcile yourself to a massively truncated version of Flickr consisting only of public photos.

I joked earlier that I've been "cloning" Flickr. I'm not, really. I am not actually interested in cloning Flickr. I am not ready to imagine a world without Flickr.
Nor am I really interested by all the talk of distributed and federated social networks or "seamless" sharing. Given how badly some services behave I can see the desire, or even the need, for an alternative to a centralized system.
I also know that it is possible to build a centralized system that doesn't suck. It is hard, but possible. And when they work they have real and tangible benefits.
But behind all of that is the question of the how and the where and ultimately the responsibility of backing things up – of personal archives – in a world with those centralized services.
I remain fantastically proud to have worked on something that enjoys the kind of confidence and good will that Flickr does.
But if I had to do it again I would spend more time trying to encourage the idea of shadow copies of a service and of an on-going personal archiving of that service. Not as a sign of weakness, or a suicidal business practice, which is usually how these things are interpretted but as a shared responsibility and a fail-safe with users.
I hope that there are some lessons in parallel-flickr that can be applied to the future but it is still early days. There's a lot left to figure out when it comes to archiving something as big and as complex as Flickr.
parallel-flickr is just one attempt to wrestle with the problem, in code and in public, and I hope there will be others.
Thank you.
Later on in the day Aaron Ximm, from the Internet Archive, did a presentation about some of the work they are doing to preserve social websites on a per-user basis. He summed up part of the Archive's reasons for doing this by saying: ...services are unmovitated to invest in the emancipation or preservation of our data.
.
I'm really glad he said that because it does a much better job articulating the problem that I was trying to touch on at the end of my own talk. Historically, services have been lax or reticent in encouraging users to think about what they do on, or with, a service outside of the service itself. We should change that.
(A PDF version of the slides and an appendix of links lives over here.)
This blog post is full of links.
#pda2012Accidental Shadows

This is the blog post where I start by slagging David Hockney (just a little) and then go on to talk about my own work. This is an awkward thing to do but there you go.
While I was in London, last, Chris Heathcote was kind enough to take me to see the big ass David Hockney exhibition currently on display at the Royal Academy. The show is epic in scale. It goes on forever and the size of some of the works make most big
paintings look like postage stamps. It is also, in turn, a rousing defense of the curator. If ever a show was in need of a critical third eye this is it.
That some people will say the same thing about some (all?) of the blog posts on this site is not lost on me and so it is worth pointing out that the Royal Academy enjoys basically the same privilege that weblogs do, the privilege to say: It's my party. The Royal Academy is not a public institution but an invite-only artist run gallery that just happens to own a giant old-skool building in center of London. They can do pretty much whatever they want and who among us, given the chance, wouldn't take a similar opportunity and run with it?
My problems with the show are three-fold: The slap-dash inclusion of earlier works not unlike the way long running TV shows will show a Previously on...
trailer at the beginning of every episode; The sausage-making death-march through every single failed study and sketch, as if the rhetoric and myth of the Artist (not to mention the bucolic English landscape) could hide the laziness and general awfulness of some of the paintings on display; The iPad paintings
. Oh god, the iPad paintings...
I genuinely admire David Hockney's work. He is a proper King Hell painter (one of only a few out there, these days) and the RA show could have been complete with the dozen, or so, really good and novel paintings he's done in the last decade. Even when I don't like a particular batch of work he's done it is hard to ignore how completely and thoroughly he gets into things, often dismantling whatever medium he's working in and showing you something you never would have considered possible.

But that does not excuse the iPad paintings. If you can even call them that.
Of the last rooms in the exhibition one is an enormous space with a ten by twenty-five (-ish) t oil painting filling an entire wall. It's a recent painting and it's beautiful and despite being a Hockney
clearly new territory, as though he had fallen in to a vat of Hundertwasser and was letting himself dry off in the sun.
(Unlike the logs
painting with its doofy Starry Night trees which are just, well... doofy.)
The rest of the room is ringed by a series of two by three t canvases stacked two high. They document the month or so in which Hockney discovered and then mastered
the iPad as painterly medium. If you call simply making high quality ink jet prints on canvas some kind of mastery. I have no idea if anyone bothered to do any colour correction for these things but it doesn't look like it. If they did it only means that the actual works themselves are that much worse. By the time you walk the length of the room you can start to see that Hockney has acheived a measure of control over the tool and, with that, he is able to do that thing with colour that give all his paintings life. But nothing is really that good and most of the earlier pieces are little more than banal art school panderings about mark-making or, in Hockney's case, discovering the rake
brush or the blur
tool.
None of which prepares you for the room that follows.
Dramatically smaller in size it only contains five or six landscapes drawn on the iPad but printed as monumental scrolls hung from the wall. I have no idea what the artist was thinking when these were done. I comfort myself by imagining that he came to America and spent time with the works of Fredric Church and thought he'd try the same but in the style of Chinese landscape painting and with the skill of a bad birthday cake painter.
Part of the reason I've gone to such hyperbolic lengths to describe the printed iPad works is that sandwiched between those two rooms is a tiny little alcove with sketchbooks under glass and five actual iPads bolted to the wall. Each is running a slide show of Hockney's iPad drawings. In their natural form. And they are wonderful. Some are more saccharine than others but they're landscapes so you just look beyond that and enjoy the spectacle of Hockney's skill as a craftsman.
Which raises a couple of interesting questions. First: Seriously what the fuck is up with those stupid canvas prints? Second: How long will it be before Hockney, or some other artist, builds a second-screen
application (that's fancy talk for your iPad, Apple TV, digital frame or any other similarly screen-ish device connected to the Internet) and offers a subscription service that blats a new work to you every day?
Because, really, Hockney's already done it. Writing in his own review of the Royal Academy show Daniel Soar points out that:
At one point during his experiments in iPad art, he was beaming new pictures of flowers daily to the Fondation Pierre Bergé-Yves Saint Laurent in Paris, where they reappeared on the screens of iPads in a show called Fleurs Fraîches. That was a proper joke.
It's sort of a no-brainer. And a fascinating way to think about creating a sustainable source of income to allow, even in part, artists to produce works are genuinely expensive in time and cost to create. It should also prove to artists, and anyone who frets over the illusion of print rights, that they've got nothing to worry about. This stuff is an entirely other material and colour made of light, it turns out, doesn't just magically translate to colour made of pigment the way that, say, a word-processing document does. And if anyone is really going to lose sleep over the people who are already predisposed to print things out on their shitty homes printers my only advice is to give up now. Let them and understand that there are more interesting problems to solve and if projects like 20x200 are any indication there's a whole world of people who want to help with not only their moral support but their wallets.
This is the part where I talk about my own work. This is the part where I suppose I open myself up to exactly the same kinds of criticisms I've leveled above but why not play it loud, right?
I haven't done any serious painting in ten or fifteen years, now. I'm mostly okay with that although I still miss it and so drawing on the iPad has been an interesting experiment indulging the illusion of painting without any of the hassle of the medium, like waiting for paint to dry. Paint drying always seems like a bit of a platitude but it's also the reason why painters flocked to acrylic paint when it was introduced, many of them suffering the awful chalkiness of the medium for the speed and ease with which they could now work compared to oil painting. As much as painting is about colour and brush strokes painting is about layering. It is about the joy in the application of those layers in broad, easy brushstrokes and all the other layers beneath peeking through. They are the accidental shadows that hold a work together. From a purely mechanical and brass-tacks point of view a painter's inability to wait for those layers to dry and take on more paint without turning to mush is probably the single biggest reason works get ruined in process.
And so the iPad with its big friendly finger surface and its millions of colours and its ability to layer ad infinitum is an attractive draw. It has no texture (no, really), no volume and no way to catch the light beyond an annoying glare but it also has enough attractive qualities that maybe it's an entirely new medium in which to work.
That's what I've been telling myself. It's what I told myself last year as I was doing a series of drawings on the iPad. There were the Space Claw for Mayor drawings and a revisiting of the Ice Cream Drawings, first started on the earliest Nokia tablets during meetings at Flickr, and a few others in between. Which is all well and good but I am also old fashioned (or maybe just old
) enough not to trust electricity or have faith in the longevity of the device in which these works exist; I have a hard time believing that there's an actual thing present when I look at the works on a screen.
The screen seems like little more than a representation which, I know, doesn't make any sense but there's the rub, eh? So, I've decided to try printing some of them in very small editions for sale as a way to push them out of the nest and see what happens next.

And when I say small I mean tiny, at least by the standards of prints and printmaking on the web today. There are eight different prints, signed and numbered, printed at two sizes: The small prints (8.5 x 11") are editions of 7 and the large prints (13 x 19") are editions of 3. Those are the magic numbers in printmaking but don't ask me why. If I ever really knew why there is something special about editions of 3 and 7 I've long since forgotten but I needed to give myself some kind of limit so that's what I chose.

One of the things I learned in the process of making these prints is that digital printmaking is just as stressful and just as boring as doing any other kind of analog printmaking. There is nothing obvious about taking a thing done on tablet and translating it to print and the proofing process is usually a frustrating grind of adjusting colours for the light and the paper, of choosing and ultimately giving on different papers, of waiting for ink to dry. My friends all have the artist's proofs to back up this claim.
This was, it's probably clear by now, the most frustrating part of the iPad paintings at the Royal Academy show: It just didn't look like anyone gave the process of taking the works from one medium to another any thought. Or rather that the works were purely an intellectual exercise (or a cheap device to illustrate how unstoppable Hockney's dance moves are) devoid of any actual qualities as paintings or drawings or whatever you want to call them.
It's kind of an exciting time, right now, so maybe we should make an effort not to squander it.

In the meantime, my prints are over on Etsy and that's all I'm going to say about it for now. It's a start, anyway.
This blog post is full of links.
#shadowsHeadless Features
This is a blog post that I've being trying to write for ... six or seven months, now. Rather than dragging it out any longer I'm just going to publish the images which tell the short version and leave the rest for some late night over drinks and napkins. Ultimately, I am hoping that by not including any text I can get Myles to use the images below as source material for his Battle Decks presentation...






This blog post is full of links.
#headless