The only thing left to do was sign the script. Digital certificates are and almost sure-fire way to kill interest in a project but sometimes its worth the pain. If you've been thinking about learning how to sign a piece of JavaScript, I have two pieces of advice for you. First, stop right now. Second, give me a couple days to finish writing the tutorial. Signing JavaScript is not actually that hard but it is a maze of twisty gotchas none of which are especially well-documented or gathered together in a single document. If this project yields nothing else I hope that it will at least save people the time it took me to figure out how scripts are signed.
Both the delicious and languid API implementations will need to be signed; life has been accelerating at a frightening pace lately but I will try to squeeze this in soon.
Last week, I finally got everything in order and successfully signed my
code. The good news was that my test
page now worked on a remote server. The bad news was that my
clever bookmarklet continued to fail when I tried to use it on the
New York Times website. The site nytimes.com, apparently, was
denied UniversalBrowserRead privileges. Since I was
working in a public place I was unable to do the unhappy,
hissy-fit dance that everyone who works with computers does when
they think they understand a problem but their program still fails.
To ensure security, the basic assumption of the JavaScript signed script security model is that mixed scripts on an HTML page operate as if they were all signed by the intersection of the principals that signed each script. This is very important in Mozilla. If you have a web page with signed and unsigned code, the entire page will be regarded as unsigned.
It's not like I hadn't read this passage before. It just went in one ear and out the other because, at the time, I didn't think I would need to worry about signing anything. Lots of websites, including the New York Times load a variety of scripts for doing browser sniffing, dynamic page-layout or advertising hacks. Since all the JavaScript code in a page operates in the same virtual environment, with the same permissions, Draconian assumptions about signed and unsigned code make perfect sense. You can be pretty sure that if a ne'er-do-well were able abuse the permissions granted to a script other than their own they would.
Sadly, manipulating a page's DOM to remove all
its script elements does not affect already compiled
JavaScript code. Good practices aside, once loaded in to
memory there is no way to strip exisiting code from a page.
// First, strip the page of all its scripts
// This doesn't actually work; the elements
// are removed but not the code in memory
var list = document.getElementsByTagName('script');
var len = list.length;
for (var i = 0; i < len; i++) {
// because list is updated as the
// script's parent removes each child
var script = list[0];
script.parentNode.removeChild(script);
}
// now squirt the signed script back
// in to the DOM
var new_script = document.createElement('script');
new_script.setAttribute('src','jar:http://example.com/flickr-tags.jar!/flickr-tags.js');
void(document.body.appendChild(new_script));
I'm not sure what the right way to handle this is. There are probably games to be played with frames and pop-up windows (hmmmm....) but each one takes something away from the elegance and the simplicity of the original idea. Having the option of creating individual sandboxes for one, or more, scripts in a page sounds attractive but I have no idea whether its feasible and I wouldn't hold my breath waiting for it.
At the moment, everything suggests that my clever hack can't be done, at least not reliably, securely and from a bookmarklet.
{kind=link}
{kind=link}
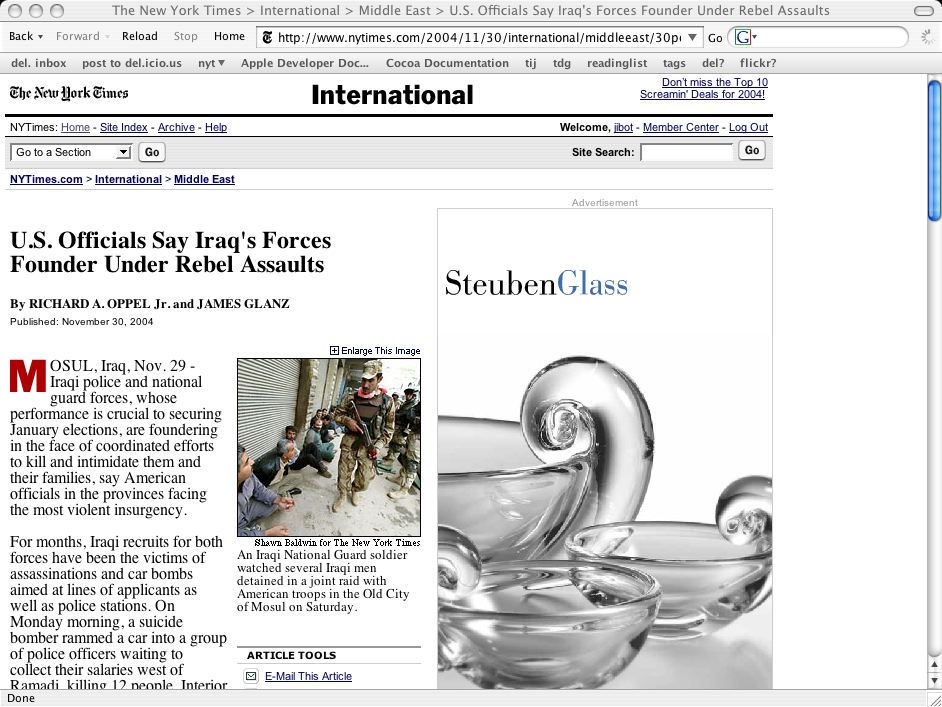
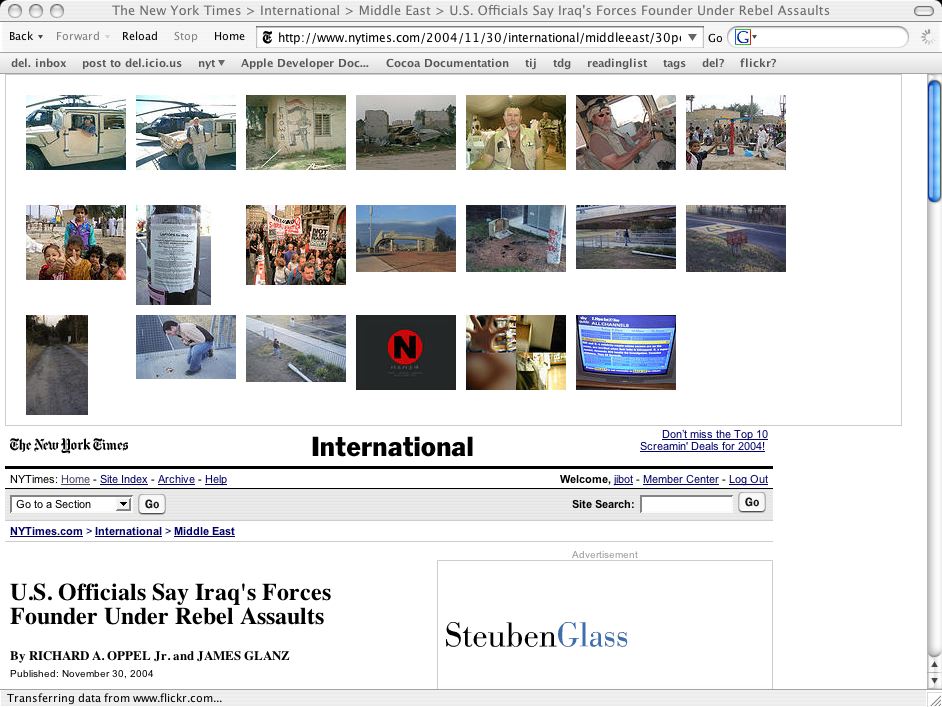
A couple weeks ago, I started huffing the JavaScript XMLHttpRequest-DOM glue. I implemented the del.icio.us and languid APIs as an appetizer and, once I got the hang of it, turned my attention back to a project of long-standing interest : mapping specific <meta> tags embedded in a document's header with corresponding Flickr photographs and updating the page's DOM on the fly to display them.
I wrote the code. It worked. I did the silent dance that everyone who works with computers does when they figure something out. Then I moved the code off my local machine to a remote server and it stopped working.
netscape.security.PrivilegeManager.enablePrivilege('UniversalBrowserRead'); var flickr = new FlickrTags (); # these are the topics that the New York # Times uses; you could just as easily # say : flickr.add_topic("delicious"); flickr.add_topic("geo"); flickr.add_topic("des"); flickr.add_topic("per"); flickr.add_topic("org"); flickr.draw();It stopped working because calls to the
XMLHttpRequestmethod requesting a document outside the current page's require an initial call to the security widgets to allowUniversalBrowserReadpermissions. The list of scripts that can even ask for increased permissions is severely limited : those which are loaded from a user's hard-drive — orfile:///URLs — and those signed with a digital certificate. This is a Good Thing, albeit a pain in the ass. If any random script on the Internet could ask for, and receive, the ability to perform sensitive actions we'd be in bad shape. At worst, the security model would be rendered moot. At best, a user's on-line experience would be shot to Hell since browsers are hard-wired to display a dialog box confirming the request.For the sake of thoroughness, there is a third way which is to grab your browser by its throat and disable the default restrictions on who can demand privileges :
# file this under : you might as well be using IE # if this is how you feel about browser security. user_pref("signed.applets.codebase_principal_support", true);All of this work was done in Mozilla. I don't have a copy of IE handy and no one, including my friends who use it on a regular basis, have any idea where JavaScript error messages are logged in Safari.
I think the meta-data/Flickr/DOM hack is pretty cool in its own right, but it's only really exciting as a bookmarklet. I want to be able to browse any webpage and call Flickr to, literally, see what the rest of the internet about it right there in the same page. That, to me, is the promise of the network. That is why I am still here.
The layout of the images is not very elegant. In the context of the New York Times, it was a good 80/20 solution until the code had been properly tested and I could turn my attention to design issues.