
multiforms

I made a thing. I made a thing that most of you can't see outside of photos and screenshots, yet. But I made a thing and I want to remember making it. First, a quick bit of history.
Back in 1999 Stewart Butterfield and friends created the 5k competition to celebrate the art and craft of websites weighing in at 5kb or less. To put that in some perspective even The Mirror Project which was in its heyday at the time allowed you to upload photos that were a whopping 32kb in size.
Quoting from the competition's about page:
The idea behind the contest is that the rigid constraints of designing for the web are what force us to get truly creative. Between servers and bandwidth, clients and users, HTML and the DOM, browsers and platforms, our conscience and our ego, we're left in a very small space to find highly optimal solutions. Since the space we have to explore is so small, we have to look harder, get more creative; and that's what makes it all interesting. Just celebrating that is all.
There's a good article about the project on A List Apart.

One of my favourite entries was Heather Champ's random rothko
which, along with all the other entries, is still viewable thanks to the Wayback Machine. All it does is choose three random colours from a fixed list and then generate an equal number of stacked landscape-shaped rectangles so as to look like one of Mark Rothko's so-called multiforms.
14 years later I decided to do that same thing but using the set of primary colours derived from uploads to oh yeah, that instead of a fixed set of colours. It also uses a fourth colour and the CSS3 box-shadow property to create the illusion of a fuzzy background.

It's just a plain vanilla webpage that can run in fullscreen mode on your phone or your tablet or your desktop. It can also be plugged in to Todd Ditchendorf's Fluid.app tool to create a standalone application
if you use a Mac.
I've made two versions: One that changes as people upload new photos. The other just randomly cycles through all the photos that have ever been uploaded and creates a new multiform every 60 seconds.

That's it. It doesn't do anything else and that's part of the charm for me. It just sits in the background running in second-screen-mode stamping out robot-Rothko paintings. Having recently shuttered Pua (at least for the time being) it's nice to have a new screen friend to spend the days the days with.
Now that I've written this blog post it occurs to me that it would be trivial to build something similar on top of the Cooper Hewitt Collections API — since that's ultimately where all this colour stuff comes from — so I will probably do that shortly and stick in it the Play section.
Update: And then I did.
This blog post is full of links.
#multiformsdog-eared

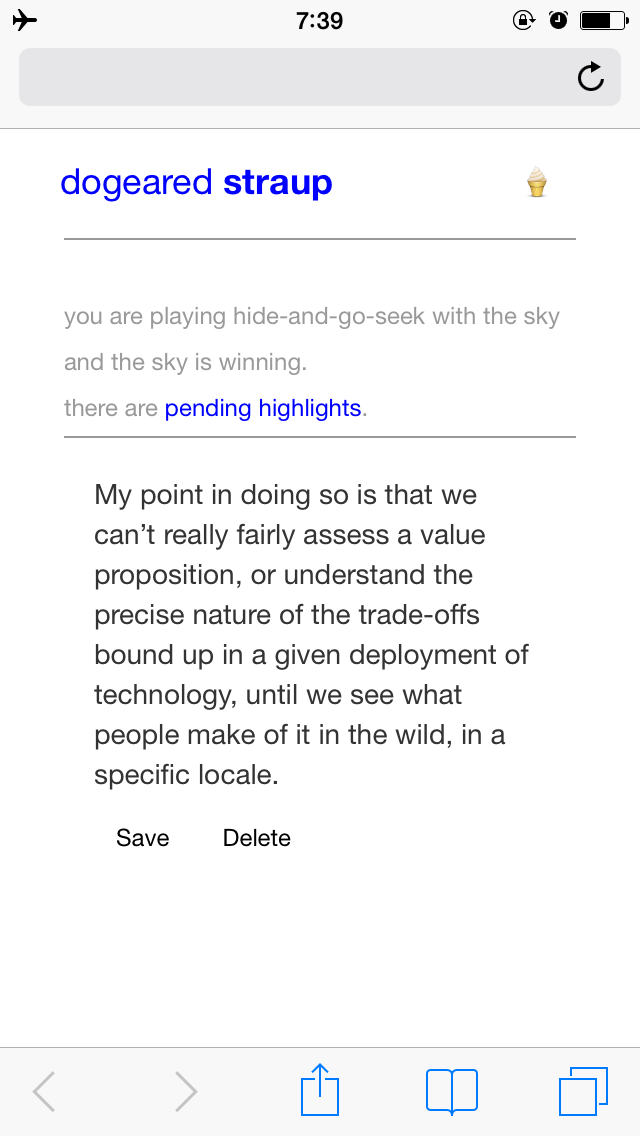
tl;dr Offline readers are on everyone's mind, these days. I made my own. It's a plain vanilla HTML+JS+CSS web application that holds hands with an equally vanilla LAMP+API server. It's probably too soon for anyone else to use but it works. Like it works underground on the subway where the Internet still don't shine.
I made a kind of peace with the Kindle when I figured out how to grab a copy of all my highlights and print them out as a book
at the end of every year. Then we moved to New York almost two years ago and because I have a long commute I do even more reading than I used to and I quickly understood why Instapaper, like Foursquare before it, was created in New York City.
Almost everyone here spends somewhere between 30 minutes to 2 hours a day underground without a network connection and without much to do except hate all of humanity, stare awkwardly their fellow travelers, play Candy Crush (seriously... what the fuck?) or read. To put that in perspective when I had my "dogeared #2013" book printed at the beginning of the year it weighted in at a hefty 736 pages. Most of that was from Instapaper.
If you ignore, for a moment, the fact that Instapaper just launched their Highlights feature you might be wondering how I managed to get 700+ pages of highlights out of Instapaper. The short answer is: Email.

In what will surely seem like a-non-sequitur-but-trust-me-it-isn't about a month ago Paul Ford and I were invited to sit in on Dan Phiffer's Javascript class at CUNY. We were talking about APIs and building applications on top of third-party services and I tried to make the argument that email was the "original" API. Or more specifically it is the one piece of functionality that comes the closest to being available across all the platforms and all the applications. Almost every app has the basic ability to send
itself (or whatever it is you are looking at) as an email. Also email has a stupidly easy user interface.
Email is the copy-paste of the Internet. It is passing notes in class. It is writing postcards. It is no less the place of manifestos or the mystery of language and all the hand-written letters before it regardless of its delivery medium. It is a conceptual framework that affords more than the alternatives and even where it fails it still demands less than other choices and so it still comes out ahead of everything else. It is hardly perfect but built-in to its use is the idea that the person at the other end of a message isn't a complete idiot and can fill in the blanks, or just hit reply and ask you to elaborate if they can't.

There isn't much to sending or receiving email and that's sort of the point.The next time someone tells you email is "dead" try to imagine the cost of investing in their solution or the cost of giving up all the flexibility that email affords. Whatever the merits of another tool when someone sets up email as a straw man it is worth questioning whether they are just passing off engineering decisions as philosophy.
For all that we enjoy a world of native hardware accelerated applications and their well-designed sexy swooshy-swoosh user-interfaces you are sorry out of luck if you need to make a "mobile app" - even ones as exceptional as Instapaper - do anything it doesn't ship out of the "app store" already doing.
I don't think there's any one party to blame in all of this although the operating system / hardware vendors continue to suffer a deficit of imagination that makes them too afraid to consider any sort of model with users and developers beyond rent-seeking. In this regard Android's shared intents
framework where third-party applications can register themselves as being capable of and interested in handling particular types of events (send to, edit with and so on) should be applauded.

Whether or not all applications register a send-by-email handler when an piece of text is selected is up for grabs but Instapaper does and so I wrote myself an upload-by-email handler which is like an API by any other name. The upload-by-email handler then turns around and posts the highlight to Pinboard. At the end of every year all those highlights (and bookmarks) are hoovered in to a database on my laptop and the highlights are extracted and formatted as a PDF file which is then sent off to be produced as a printed book.
Tom Armitage's pinboard-bookmachine is a similar set of tools for generating a book of all your Pinboard links and Alex Foley has written a good blog post detailing how to use it.
Like the Kindle before it, I was able to make peace with reading everything in Instapaper confident in the assumption that since the Betaworks acquisition my every tap and scroll is being analyzed and resold by machines. Whatever you think of that part of your relationship with Betaworks the sheer volume of work they have done since they acquired Instapaper or simply continue to support in order to un-stupid-ify websites and just deliver the substance of a page rather than the experience
usually makes the costs acceptable.

And most important of all I was able to be comfortable with the trade-offs precisely because there was a trade-off: I had a way to get the things I did in Instapaper back out again.
All good. Except for the part where the knowledge, or the sense, that you exist to service other people's algorithms or increasingly their National Security Letters is never really anything you get used to.
And the part where Instapaper can't parse PDF files. That part totally sucks.
This has always been a pet peeve of mine since I started reading a lot on my phone. On your phone PDF documents are basically the enemy; their pixel perfect layouts requiring an endless parade of pinching and panning and zooming and just generally fucking around in order to actually read anything. Which is madness since it's a PostScript document and the raw text is in there somewhere just waiting to be displayed in any number of ways.
This was brought home to me in August 2013 after a Federal District Court wrote an opinion on the legality of the New York's stop-and-frisk laws. The decision was published as a 198-page PDF file. That's 198 pages of debate about motive and individual freedoms and how communities judge and police themselves that I would absolutely read. If only it weren't a PDF file. Ever since then I have been trying to shame the NYPL Labs in to running a PDF-to-text service for precisely these kinds of documents. Wouldn't that be an awesome public service?
So about six months ago I wrote a little Java daemon called dogeared-extruder. Basically all it is is a little bit of scaffolding around three "content extraction" libraries. They are boilerpipe and java-readability which both aim to implement Arc90's "Readability" functionality and Tika which is a general purpose some-file-to-metadata-and-content tool. Tika can handle image files or word documents and URLs and insert happy-dance here PDF files.

dogeared-extruder does not do very much, by design. It accepts a URL or a file and tries to parse and it returns the data as moderately formatted HTML or a blob of JSON containing things that look like paragraphs. dogeared-extruder, or more specifically the tools it invokes, does not do anywhere near as good a job of extracting text or cleaning up webpages as either Readability or Instapaper.
From the very beginning the idea was always to build a separate website that could do some of the things that Instapaper does (mostly just keeping a list of things you want to read) and using dogeared-extruder as a service, passing in URLS and getting back blobs of text for doing stuff with. That way there would be a nice clear separation of concerns between things. The text extraction piece could be worked in isolation from all the interaction and related considerations for doing stuff with that text, as you'll see below.
Update: For example, last night I discovered Thomas Levine's How I parse PDF files which looks to use Inkscape to do most of the heavy-lifting.
In the process I started thinking that if the user-facing part of the website was just receiving and storing bags of paragraphs would it be possible to also store that data on a client using a web browser's local storage functionality? Not in the abstract but as a living breathing application that I would actually use on the subway in New York City going to and from work. An offline reader, but built as a web application.
The answer, it seems, is a tentative yes
. It consists of a standard web server and database and API setup and a whole lot of JavaScript to deal with fetching and caching documents and trying to do the right thing when the network goes offline.

In addition to using the browser's local storage database the code relies heavily on the still nascent application cache (sometimes just called "appcache") feature-set to work. Quite a lot has been written about how appcache is weird and fussy and often broken most notably Jake Archibald's Application Cache is a Douchebag.
Most of what was written back then still applies but things feel like they are getting a little better. Mike Radcliffe's Application Cache is no longer a Douchebag was very helpful for getting a grasp on the current state of affairs. That said, appcache still relies on and remains hyper conservative about the way it interprets the manifest file listing all the bits of the application it needs to cache locally.
If you can change the contents of any file - and that might include the list of documents in your reading - you need to somehow update the contents manifest in order for the browser to reflect those changes. For example:
- Every time you change one of the JavaScript or CSS files. This is handled by a combination of the
make buildcommand and theincrement-manifest.shscript that updates the manifest's "version" number. - Every time a new document or highlight is added. This is handled by updating the manifest which is generated programmatically by inserting a timestamp of the user's most recent activity. Maybe? Sorta? See notes below about the one-page Javascript applications...
- Every time one the site's time-sensitive OAuth2 tokens (bound to the currently logged-in user) rotates. We deal with this by hash the token details in to a unique-but-reproducable-during-the-tokens-lifetime piece of gibberish.
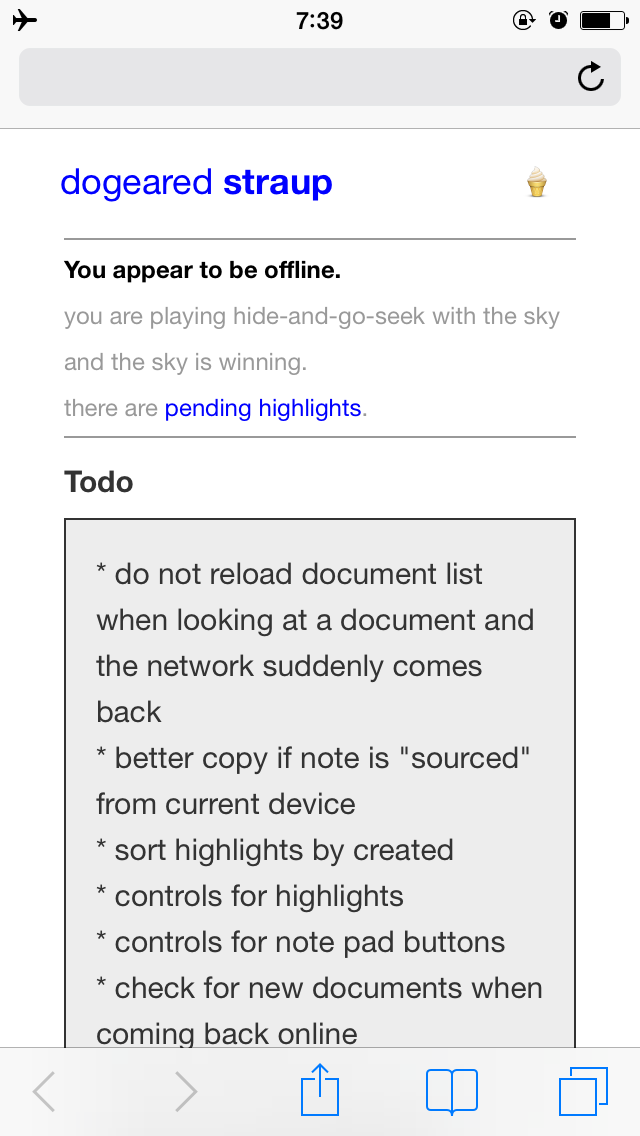
All of which made me change the document loading code so that documents are always retrieved from the local cache and (if possible) after an initial API call to refresh list of documents to be read. This is not ideal and means I've written one of those dreaded one-page JavaScript apps that always load with an empty page before getting around to displaying any content. It's possible that the only thing you should send server-side for a thing that uses appcache is the shell, leaving the entirety of your logic in JavaScript.
I am not happy about this but given the fussiness around how a user's reading list gets cached when that data is written to the page server-side it seems like an acceptable poison. For now.
And it's not like any of this is implemented (or broken) in any seemingly consistent way across different browsers. The lack of any sort of verbose console.log style debugging to introspect what the browser is doing and thinking makes developing application cache based applications pretty frustrating but we can always hope those tools with start to appear over time.
Update: Jake Archibald wrote to mention the first draft of the Services Worker spec which looks interesting. At a glance it seems sacrifice the ease of maintaining a declarative manifest file for a whole lot of JavaScript callbacks and abstractions in order to be able to do better debugging (or advanced tom-lery) which makes me think that most of the issues in the Application Cache spec could just be fixed with better introspection. The problem, fundamentally, is that there's no window on what the browser thinks is going on and I'm not sure how Service Workers improve that.
It's super early days and not anywhere near as elegant in its user interface or user interactions as Instapaper is but it works. It works in that way a proof-of-concept works. It works until it doesn't. It works technically but it lacks the attention to detail that makes its working-ness transparent. It works in that way that there is something tangible to make transparent now.
- It doesn't have swooshy-swoosh touch events for moving between documents.
- Highlighting is only just sort of becoming a native element in JavaScript and it's certainly not configured to easily trigger actions so all the "save this selection" is home-grown and full of bugs.
- The highlight button itself is inserted directly after the text, rather than hovering over the text, so you can easily end up with annoying text reflow issues. This is especially true when you are trying to highlight a passage at the end of a paragraph because the highlight button gets in the way and then the operating system tries to helpfully select the entire paragraph for you.
- Selecting an entire paragraph in WebKit cause the current selection in JavaScript to be flushed because ... computers?
- None of the buttons are particularly well-suited for lazy thumbs on mobile phones yet.
- It doesn't remember where you left off in a text so there's a lot of scrolling involved in using the app.
- It doesn't send highlights to Pinboard and you can't easily share articles or highlights with people. It doesn't even send email yet.
- There is no simple one-button export although there is an API that the site itself uses if you're so inclined to built an export tool yourself.
- Because you track text selection in Mozilla using
onmouseuprather thanselectionchangeevents it's easy to forget to ignore things that aren't thehighlight
button. - The relationship between
dogeared.documents.jsanddogeared.document.jsand all thedogeared.cache.*.jslibraries needs to be reconsidered and possibly refactored. - Even though
extruder
service allows you to upload local files to be parsed that functionality is not yet parse of the website. - Nothing is encrypted so you are the mercy of your browser's security policy (if any) around the local storage database. There's probably some lessons to be gleaned from Aaron Boodman's Halfnote project (circa 2006) to create an offline and encrypted notepad.
- Oh, and you need to set it up yourself and that includes running the extractor as a standalone Java daemon.
It doesn't so search yet, either. Unless someone else wants to do it themselves, search is at least a few months away. It will probably Solr, maybe ElasticSearch. The medium-term goal - like before search is complete - is to figure out which pieces can be run on top of existing "application" servers like Heroku (dogeared-www should be easy enough now that ApacheScript is supported as a first-class application environment) and to "container-ize" all the rest using something like Docker or any of the other push-button-unix-server-as-a-standalone-application tools.
But it works. You can read documents synced across devices and the application (mostly) degrades and recovers gracefully with the availability of network access. And it works equally well in the browser on my laptop as it does on my phone.

Somewhere along the way I ended up adding "notepad" functionality to the website. This feels like a bit of a side-car and may eventually be moved in to a separate application but it turns out I also do a fair amount of writing on my phone while I am underground so it seemed like a good use-case for further testing the same techniques used to build an offline reader. Most of the first draft for this blog post was written using the notepad feature while on the subway.
Did I mention I ride the subway a lot? I am starting to think of the subway as cross-training for the grim meat hook world where the internet we all knew and loved has been taken away from us.
There's nothing particularly magic about it. Like nothing. It uses the same "local storage" hooks to keep notes on the device and simply inserts the body of the text in to a <div> element with the contenteditable attribute set to "on". Text is saved locally every 30 seconds and periodically synced to a central server (this includes fetching any new notes that may have been written elsewhere) via the API for only the barest approximation of what we think counts as synchronization in 2014. It's basically just first-past-the-post with the most recent revision overwriting older ones. There is no attempt to merge documents and there is no history of changes so you can be sure that sooner or later hilarity (or disaster or both) will ensue and I will have to get around to fixing that.
Such is the way of mornings-and-weekends projects.
I used to use Dropbox and a nifty iphone app called Elements to do this. But then Elements stopped working and Dropbox just started to seem less interesting for all the usual reasons and trying to write on a laptop on the subway is generally not advised and often simply impossible given the crowds.
In the meantime I have an offline reader that can sync across devices and handle PDF files and save highlights. It also has the world's simplest and dumbest and functional notepad for ... well, notes. All in a web browser. Eventually it will be searchable and in until then it has an API that I can use to build bespoke features. I doubt that I will stop using Instapaper any time soon but now I have something to compare it to. I have a thing that not only works but is hopefully built in such a way that I can work on the details in small and manageable chunks as they become important and time permits.
The source code is available for people who want to take a look. This is alpha (pre-alpha?) quality software and there is nothing that looks like proper documentation yet. I am not sure that it won't be more annoying than not for anyone other than me at this point but you can decide that for yourself.
This blog post is full of links.
#dogeared