
24 sheets of PPPPPaper

I don't even like the Turkish map fold, to be honest. Also, this blog post is too long. And full of yaks. RAWR!
Dave first showed it to Matt, I think, who showed it George and they all showed it to me as an alternative to the PocketMod layout which is what I'd been using to build Papernet prototypes. As I said, I don't like it very much: You have to first tear or cut a sheet of paper in to a square and then there's a lot of weird folding. It's no easier to explain than the funny press-fold-turn dance step for making PocketMod books and in the end I just have something with an irregular shape and a pointy bottom that needs to be folded (again) before I can put it in my pocket.
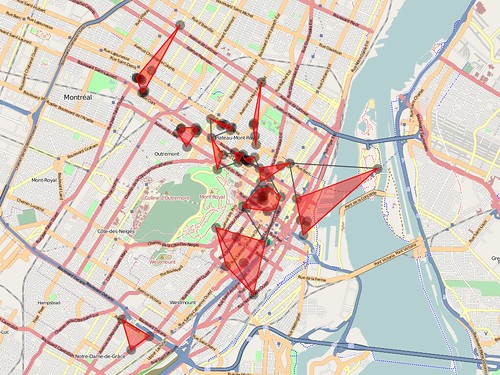
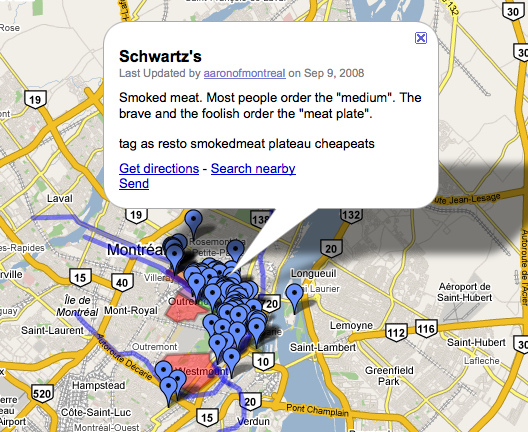
But, what the hell. I had just finished the ill-fated experiment with the pocketMMap books at DesignEngaged (DE08). I had done a quick and dirty experiment using the same code to render the Dopplr places (Atom) feed for London only to discover that it spanned 24 sheets of paper because while most of the points of interest were in central London the rest were forever and beyond in places like Heathrow. By then, I was open to George's suggestion that maybe a reasonable design constraint was to limit both the number of points listed and the area that they covered.
Strictly speaking I don't actually think that's a
useful constraint because it sort of hand waves the
problem (that you can't always best of
away a
perfectly reasonable collection of densely clustered points)
but it did seem like an interesting way to approach the
problem. The code that generated the DE08 pocketMMaps was
pretty naive in its approach: It simply created a bounding
box based on the outlier points and drew a big rectangular
map on to which restaurants and hotels and funny stories
were plotted. In practice this meant that at least half the
map surface was negative space, devoid of any markers,
because 90% of the points formed a long cresent that hugged
just one side of Mont Royal.
Lots of empty map space makes for lots of pages which makes for lots of fussing folding paper which makes for no fun.
I have seen very large Turkish maps that can be folded into the size of a cigarette pack and I have seen people glue many smaller ones together to form a book but those are capital-A acitivities and all I've ever wanted is something I could produce quickly and cheaply and shove in my pocket on the way out the door. I drank the kool-aid along with everyone else and I happen to be excited about the magic digital sensor world in my pocket but I also want something to fall back on when the computers fuck up, can't find the network or (more likely) run out of power.
Right now that's consumer-grade printers that print on letter-sized sheets of paper. And, in the case of Turkish maps, trying to squeeze 80+ points ranging a distance of everal square miles in to a single map view eight or inches across was a non-starter.
So, working off of George's suggestion of creating smaller and more intimate story-telling maps, with only a handful of touchstones and enough room for a person to discover a place, why not try to recognize clusters based on the proximity of one location to another and sort everything into groupings small enough to fit on a single sheet of paper? Remember the 32-page Word document, emailed and printed out, of restaurants and bars in Paris organized by neighbourood that was one of the sparks for the whole Papernet dance? Yeah, like that.
Which is what I'd really hoped to have finished in time for PaperCamp. It seemed straight-forward enough, at the time, which is a polite way of saying that's when the yak shaving started. Also, printers lie.
But I digress.
Most of this code gets written in a hurry, in the morning over coffee with an eye towards solving the particular task at hand rather building a possibility-space-elevator, and that was truer still of the code to make map-things for DE08. Which is fine and the price of working that way is that sometimes you need to go back and refactor everything to play nicely with a new idea. I'm okay with this largely on the grounds that this kind of fussing and nit-picking, at least in nerd/programmer circles, happens no matter what you do or how you start so there's not a lot of point in pretending otherwise at the outset.
And sometimes you get stuck solving a problem that seemed to make sense at the time but doesn't really apply anymore or is simply at cross purposes. Back when I was working on the pocketMMap code I generated the index (or table of contents) at the back as an image rather than proper inline vector-based text data. At the time this seemed like the easy and clever thing to do, though I've since realized that Report Lab can do what I need it to in pure PDF, and it proved useful because a day or two before DE08 was set to start we decided to print big maps, to hang on the wall, with big honking markers for each point of interest. So I needed something to render text in a box with a fixed size as an image.
Which was, and is, kind of a nuisance; the sort of endless fussing over details that makes print such a chore and makes people run for the warm embrace and relative safety of HTML and CSS. I get it. I really do. But at least now I can add simple (very simple) chunks of text to ws-modestmaps. Which was actually the point, just a different one.
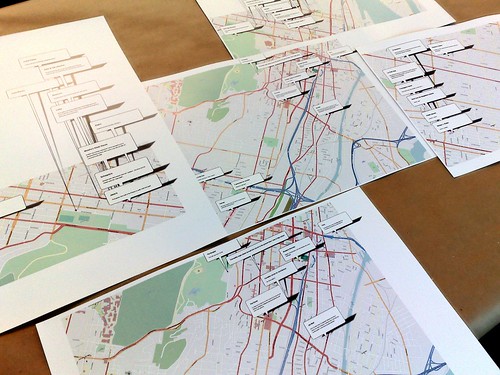
So, that was the first stumbling block: Trying to finish
an abstracted set of draw me some rasterized text, in this a box this size
functions and then
shoe-horning them into a capital-P print project. It's one thing
to write code from scratch to just work for the task at hand
and it's quite another to try and write code that can
predict the future.
As an aside, I learned during the four short days I
worked in the fast d industry that this is called
stage and project
or, alternately, capacity planning
for bad habits. I worked in a big-chain burger joint where
the trick was to always have enough burgers cooking at any
one time that an order could be served withing 15 seconds of
having been placed. The catch though was that we were
supposed to also have enough burgers on the grill that got
overcooked so that we could use them to make chili.
The second problem is that I tried to rationalize the code that generates (so-called) pocketMMaps and turkishMMaps too soon. There is now a shared library for the two packages that is classic kitchen-sink code with debatable subclasses and naming conventions that started out as an wrapper for drawing polylines and other markers on top of py-modestmaps derived images and somehow ended up containing feed parsers. Because, you know, that's where the markers came from. Yeah, I know...
The road to Hell is paved with abstract intentions.
So, that's the lesson for me. Not that there shouldn't
be a proper code cleanup but that there was nothing gained
from doing it now. It would have been cleaner and faster and
easier to use the dreaded lib_copy_and_paste
and clone entire chunks of code and made the effort to leave
notes and pointers and comments to help refactor things when
the dust had settled and not a moment before.
In the end it all works. It is really not pretty to see what's going on behind the scenes and I am less convinced than ever that it's worth .... But it works.

Printers lie.
That's what Matt Jones said to me
when we were commiserating over the pain involved in trying
to wrestle with printer margins and bleeds and the
like. There's a reason everyone got so excited about the
web: It's not print, which is full of grues and
demons. (The same reason, frankly, I still prefer drawing
maps by hand really...) In
my case, I wanted to overlay guide lines, for cropping and
folding the paper, because after all it was a Turkish map and that seemed
like a useful addition. In my case it was made worse by the
need to play stupid tricks with the over-sized page dimensions and
image resolution and telling printer drivers to scale to fit
in order to make the rendered map tiles crisp enough for
viewing and large enough to include markers without
succumbing to red-dot fever.

But, here's the thing about this approach: It sucks.
It is a situation that's gradually getting better but until recently the only alternative, if you wanted to do this stuff programatically, was to write stuff in PostScript (or LaTex, if you're Blaine) which is basically pure buzz-kill for any project. I take a some small perverse joy in seeing that all the work the XSL-FO community did, and the pain I endured to generate index-card sized (duh duh duh) printed recipes was actually the right approach. I say that having only just recently discovered that work has begun anew on FOP, the only serious open-source XSL-FO processor available.
This is a Very Good Thing because XSL-FO is designed to embed SVG which suddenly means that generating printed maps, whether it's using something like Cloudmade's decidely alpha SVG tiles or simply baking SVG maps using Mapnik, is actually well... possible enough to be considered easy.
There are also, it's true, countless HTML to PDF style converters out there but if you stop and think about it they are all just XSL-FO processors without 500-odd years of lessons learned and gotchas from the print world. This is not necessarily a bad thing depending on the scope of your project but, really, I digress.

If the original pocketMMap exercise was completed in order to figure out where it would fail, this was an exercise in trying to figure out how to start making it better without worrying too much about the shiny.
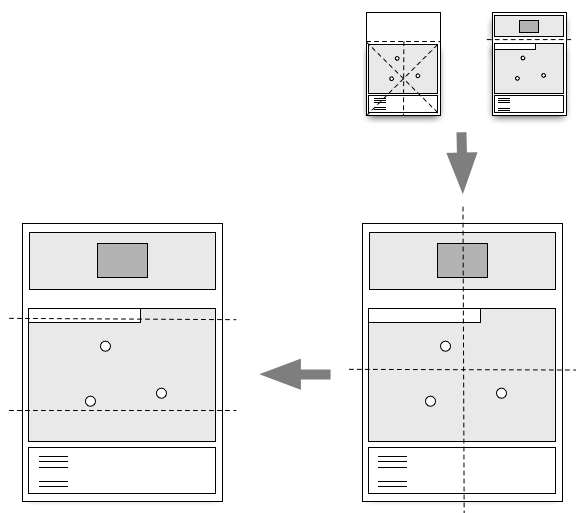
The basic design of the TurkishMMap was a square map
cropped on its y
axis enough to fit a legend containing the markers listed on
the map and a throw-away gutter at the top of the page. It's
a Turkish map, after all, so the sheet will need to be torn
to form a square. Which made trying to get all the margins
to line and be equally spaced on all four sides of the map
... a waste of time, really.
So, eventually I stopped bothering. With the margins and the fold lines. Really with the Turkish map part entirely. You can still do all of that if you want but what I started to realize staring at all my failed print-outs was, once the automagic clustering of places had been done and any one sheet of paper only had about ten items listed that I liked the layout as is. Unfolded.
Or rather, I didn't really care how it was folded if at all. As documents that are scoped to a bunch of places all relatively close to one another I can imagine printing them all out in advance of a trip (for example) and then, just like when we were in Paris in 2006, simply the grabbing two or three sheets that I think I might need during the day and shoving them in my pocket on the way out the door.
I kept the large gutter at the top of each page for those people who really want to make a proper Turkish map but also used the space to include a zoomed out map of the same area with the bounding box of the larger map highlighted to give things a little more context.
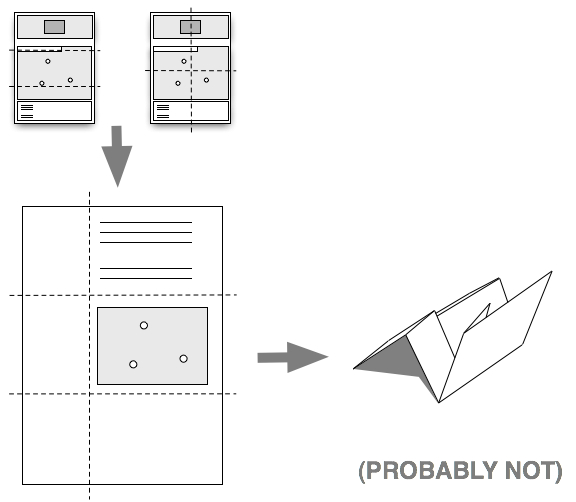
Which is interesting because you start to hear echoes of
the original Papernet mockups for recipes and
wine not that I think it's necessarily any more
useful. As much as I love all the sexy folding and magic
books that appear before your eyes the trouble they require
to make seems to be inversely proportional to the
value people place on them as a thing. It's far from a golden
rule but generally things become artifacts
in their use rather than their making (or configuring
)
and in that light it's still pretty hard to beat a single
printed sheet of paper and scribbled notes and other scraps
of paper that begin to orbit each other over time.
It doesn't necessarily make for great sharing, in the ways that we've
come to expect from hanging out on the Internet for a decade, but it's worth noting
that I live and breath this stuff and still we take the same
32 pages of stuff to do in Paris
that we first printed out
in 2006 every time we visit.
One of the last people to speak at PaperCamp, in London, was Beeker Northam and she
did a short talk about her love of books and in particular
individual pages in books. Jeremy did a good job
describing what she said next so I'll just quote him: She photographs her
books. There’s something about photographing them that’s
different to scanning them. She’d like to have some kind of
web-based way for people to share those bits of books that
have had an emotional impact on them but she hasn’t found it
yet.
This struck a chord with me for a couple reasons. First, I'd kind of like to get back to working on the web-based end of things for a while. I've spent about a year working on the output and formatting end of things and it feels like it's time to work on some of the tools for actually creating things; maybe giving the long neglected deliciousmaps project some love. Second, because it was so god damn simple and simple usually wins. I am as guilty as anyone of fetishizing the separation of form and content but maybe, just maybe, it's not such a big deal. At least not to start with.
Maybe it's good enough to just assume people will
scribble maps on the backs of napkins and eventually get
around to uploading them to some place where they can be
shared, where shared mostly means dragging and dropping on
to some sort of canvas
to be (re) printed. Rinse and
repeat. Somewhere
further down the eventuality stream those same maps could be
traced in the same way raw GPS traces
are merged in to Open Street Maps, for example. Sooner
or later someone will go to the trouble of sorting,
arranging and rectifying all the data-bits properly and then
the tools for automagically creating new things will be even
better but that shouldn't also prevent people from
doing the quick and simple thing.
I think Mike's walking papers
project
and Schuyler's work building the NYPL map
rectifier are important in this regard. They are the
bridge-pieces that let people work outside the normally
formal and tedious constraints of software while providing a
way to get all that data back into a structured
system. Which is pretty awesome, but I digress again.
The short version: It's still not possible to generate paginated pocketMMaps. Yet. In the meantime, here's what you can do:
import turkishMMap
This is the code that can, for example, read in an GeoRSS (or Atom) feed containing
80-odd points and generate a 14-page PDF file
with a separate page for the 12 distinct clusterings in to
which those points were sorted, a finishing oddballs and
orphans
page for places that didn't fit anywhere else
and a cover page listing all those pages and their coverage
area. The only difference from the pocketMMap code is that
you pass in an extra paginated=True argument:
from turkishMMap.Providers import GeoRSS
tm = GeoRSS(8.5, 11)
tm.load_provider('OPEN_STREET_MAP')
tm.draw_feed('http://example.com/points.rss', paginated=True)
tm.save('DE08.pdf')
You can download a copy of the PDF file to see the
whole thing, in its clunky rasterized glory, but here are
some sample images:
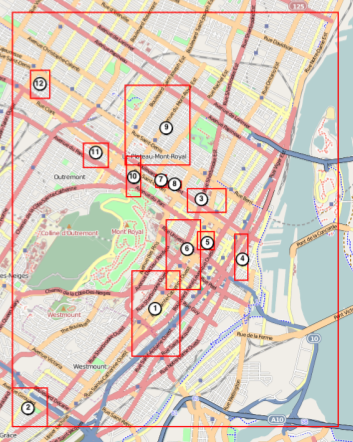
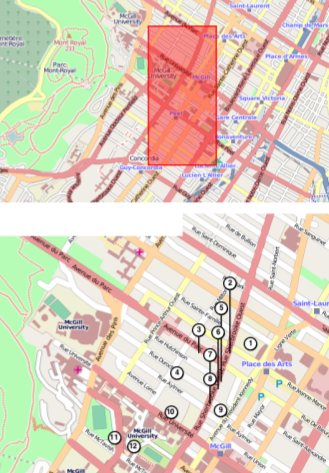
import modestMMarkers
Dear god, help me, this is the kitchen sink library
I mentioned above. It's really bad. Really. Bad. The
good news is that there is only one public
interface, for drawing polylines and markers, and that's not
going anywhere. The gooder news is that the rest will
eventually be moved in to a generic toolbox package called
something equally stupid like modesTToolbox.
The marker stuff is actually pretty useful, though. The super-quick example looks like this:
from modestMMarkers import polylines
mm_obj = ModestMaps.mapByExtent(provider, sw, ne, dims)
mm_img = mm_obj.draw()
poly = polylines.polyline(mm_obj)
mm_img = poly.draw_polylines(mm_img, polys)
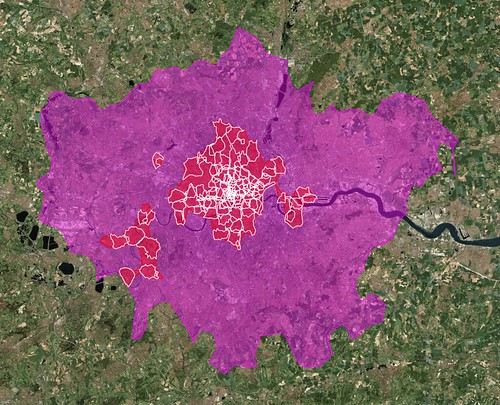
If you follow this link, I've included example code that will fetch and render the shape data (derived from geotagged photos on Flickr) for a given WOE ID as well as all the child WOE IDs contained within, and plotting the whole on a handy background map. When you run it you'll end up with something like this:
import clusterMMap
This starts off as plain old K-Means
clustering where, in the absence of a user-defined value of
K, the square-root of the number of markers is
used. After the initial clustering is done the results are
filtered to prevent any single cluster from containing more than
nine points (that should probably be configurable). Any that
exceed the limit continue to be re-crunched (with a K value of
2) until they meet expectations and even then they are subject
to an additional distance test to ensure that outliers don't get
grouped with something that's actually too far away. That may
mean that they end up as orphan
points but there are
hoops to try and account for that too.
cl = clusterMMap.clusterMMap() (clusters, orphaned) = cl.clusters(points)
The clusters are then further simplified by generating a
convex hull, or more precisely tested to see if there are enough
points to create a hull. If not, all the points in that
clustered are treated as orphans. So, now we have a bunch of
polylines and orphan points. If the bounding box for any one
polyline contains the bounding box for another polyline
or the bounding box of polyline x
intersects polyline y (the actual polyline, not the
bounding box) then the two are merged. Finally, each orphaned
point is tested to see whether it is contained by any of the
bounding boxes for the remaining polylines (and added to that
cluster if it does).
Is all that work really necessary? I don't know, but it seems to work so I'll keep poking at it until it doesn't or someone offers a more compelling cluebat:
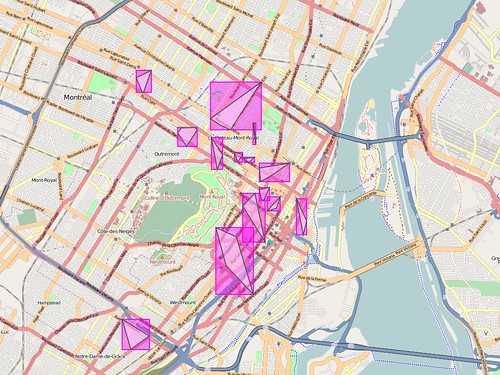
I've been known to talk about false starts
a lot these
days. I do that as much as anything to remind myself why I spend
six months holed up on these kind of projects. I'm not really
disappointed. Too much, anyway. I would prefer to have come out
of this round with something a little more polished, but at the
same time I try to remember that's part of the process. In the
end I have some useful pieces of code that I can use elsewhere,
a working prototype which is always better to help understand what to
do next and maybe a little bit of time to do something else for
a while.
The code itself is hosted on aaronland and assuming you've managed to install py-cairo and ModestMaps yourself should just magically install any other dependencies. (Actually, the clustering code requires Shapely and Numpy but there are OS-specific packages for those too.) I might put the clustering code up on GitHub but, right now, the rest seem like too much of a moving target to bother.
What's next? Aside from all the stuff mentioned above? Probably a spy novel...
This blog post is full of links.
#turkishmmap